
AI Inference engine for Openfire using LLaMA. This plugin is a wrapper to llama.cpp server binary. It uses the HTTP API to create a chatbot in Openfire which will engage in XMPP chat and groupchat conversations.
![]()
llama-chat.mov
This version has embedded binaries for only Linux 64 and Windows 64.
copy llama.jar to the plugins folder
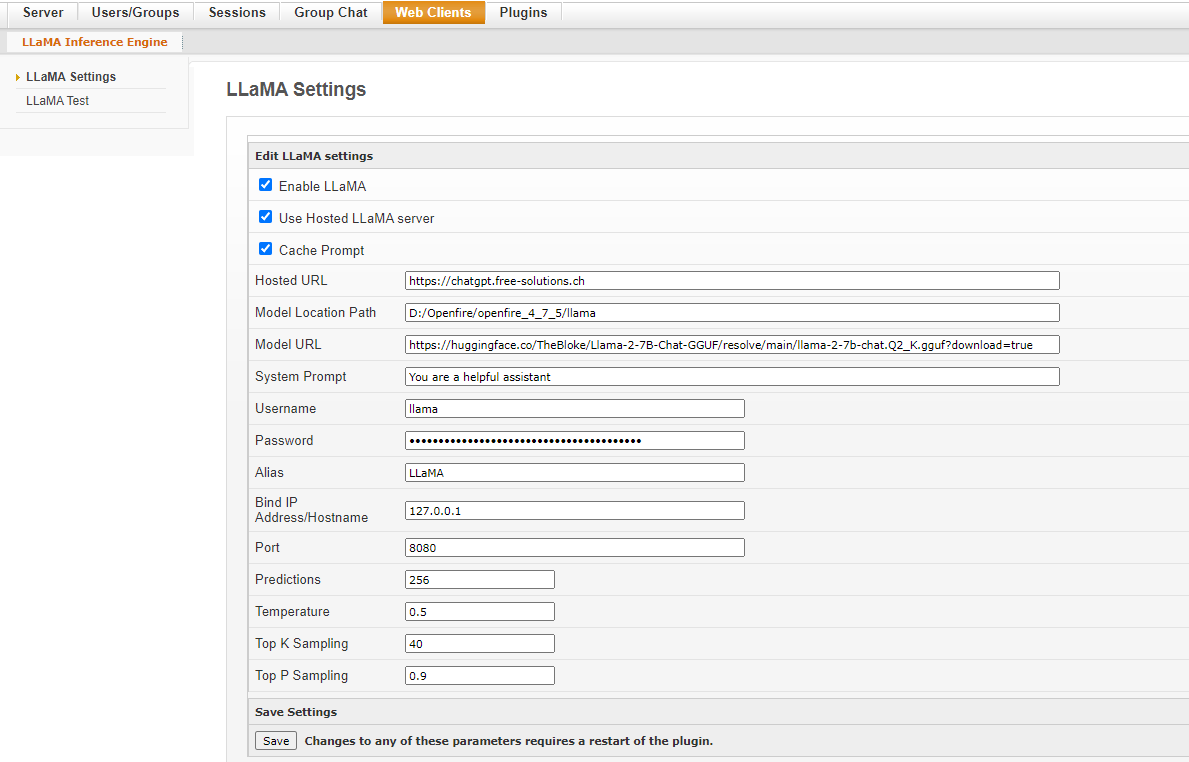
Enables or disables the plugin. Reload plugin or restart Openfire if this or any of the settings other settings are changed.
This causes the plugin to use a remote llama.cpp server instead of the local server running Openfire
The URL to the remote llama.cpp server to be used. The plugin will assume that remote server has the correct LLaMA model and configuration. It will send requests to this URL.
This is Openfire username/password for the user that will act as a chatbot for LLaMA. By default the user will be “llama” and the password witll be a random string. If you are using ldap or your Openfire user manager is in read-only mode and a new user cannot be created, then you must create the user and specify the username and password here…
Set an alias for the model. The alias will be returned in chat responses.
Set the IP address to bind to. Default: localhost (127.0.0.1)
Set the port to listen. Default: 8080
Specify the path to where the LLaMA model file to be downloaded on the server. Default is OPENFIRE_HOME/llama folder. If a model file is already available, copy it here as llama.model.gguf.
Specify the URL to the LLaMA model file to be downloaded and used. Default is https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGUF/resolve/main/llama-2-7b-chat.Q2_K.gguf?download=true The first time the plugin starts, it will download this file and cache in OPENFIRE_HOME/llama folder.
Prompting large language models like Llama 2 is an art and a science. Set your system prompt here. Default is "You are a helpful assistant"
Set the maximum number of tokens to predict when generating text. Note: May exceed the set limit slightly if the last token is a partial multibyte character. When 0, no tokens will be generated but the prompt is evaluated into the cache. Default is 256
Adjust the randomness of the generated text (default: 0.5).
Limit the next token selection to the K most probable tokens (default: 40).
Limit the next token selection to a subset of tokens with a cumulative probability above a threshold P (default: 0.95).
{kind=link}
{kind=link}
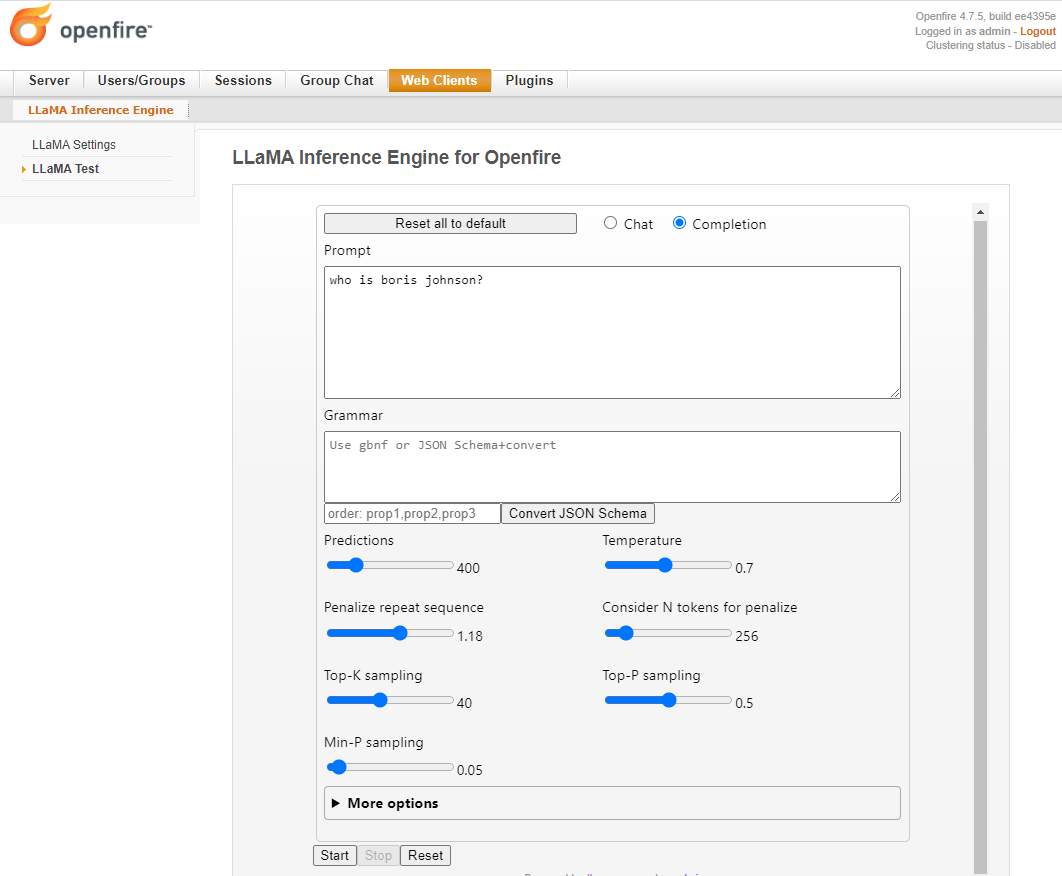
To confirm that llama.cpp is working, use the demo web app to test.
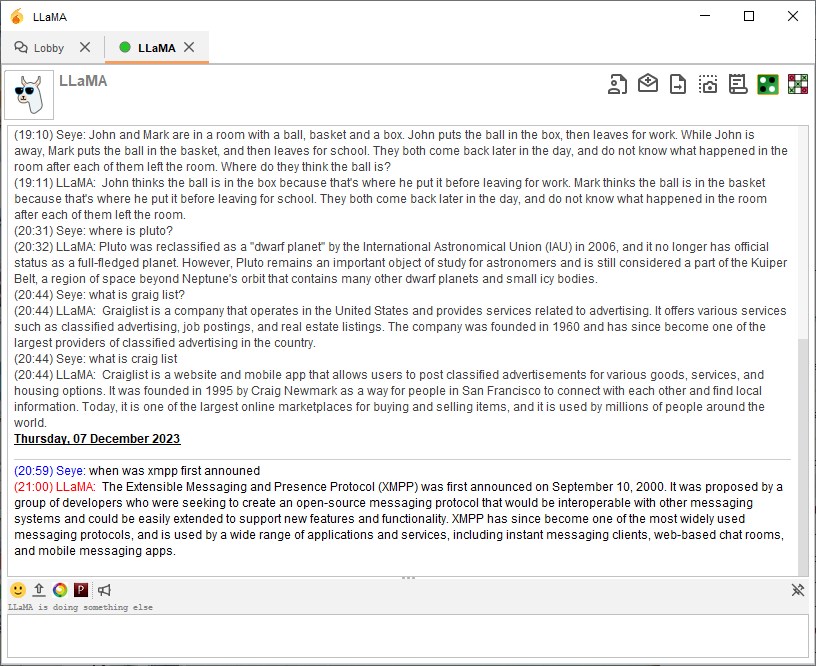
The plugin will create an Openfire user called llama (by default). The user can be engaged with in chat or groupchats from any XMPP client application like Spark, Converse or Conversations.
Add llama as a contact and start a chat conversation
(22:20) Seye: what are female goats called?
(22:20) LLaMA: Female goats are called does.
You can invite llama to join a groupchat and it will auto-accept. Type any groupchat message that starts with llama's name (llama default) and it will respond. All other messages will be ignored.

If a message is typed in any chat room locally and it starts with the llama name (llama by default), then it will auto join the room and respond the instruction or query. Note that this only works with group-chats hosted in your Openfire server. Federation is not supported.
The gguf model files for LLaMA 2 are large 5GB+ and may take serveral minutes to download. The downloaded model file is cached as OPENFIRE_HOME/llama/llama.model.gguf. To speed up this process, you can preload the model by copying a local file to this destination and rename accordingly before installing the plugin.
The plugin has generic binaries for Linux64 and Windows64 with no GPU support. In order add GPU support, build the llama.cpp server binary with the appropriate GPU configuration and replace in the OPENFIRE_HOME/plugins/llama/classes/linux-64 or OPENFIRE_HOME/plugins/llama/classes/win-64 folder after installing the plugin or replace in the source code and rebuild plugin with maven.