
Language learning word game service for infants using image cards that are generated differently each time using generative AI.
This application was created using the following libraries and frameworks.

The idea began with the mission of having children study English words in a three-dimensional way. When children study through real objects, they sometimes encounter objects from various perspectives with greater curiosity and observation than adults.
However, in an indoor study environment using word cards, there are some limitations due to its special characteristics.
In particular, through card games in physical form, children are exposed to the picture represented by the word as a 2D image drawn in only one style. To solve these problems, Sullivan-AI was designed based on Open-AI's deep learning model and early childhood pedagogy.

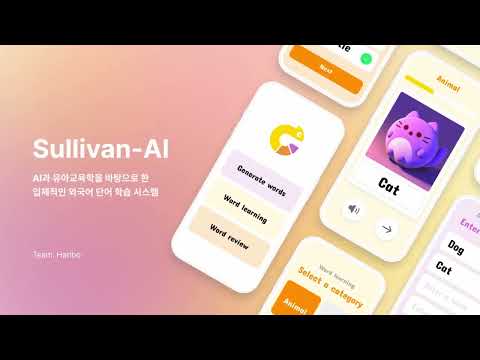
In the first stage, you learn the pronunciation of the word by looking at the given picture.
The generated picture is created with DALL-E's image generation, and you can select the word category and prompt style to determine the group of words you want and the picture style that can most effectively show the word. One category consists of 5 words, which were designed considering the child's attention span of 'age * 1 minute'.

The second stage is the review stage.
The pictures learned in step 1 are tested with similar, but slightly different images each time through DALL-E's image variation. The test is conducted using voice, and the child's voice is converted into text through Open-Al's whisper model. Let’s explain the learning process in step 2 in deep learning terms: This is to ensure that children learn robustly through data-augmenting to prevent them from over-fitting only the given data.

In the review stage, the words learned in the learning stage are transformed by the DALL-E variation model, and the reproduced images appear. When a user (baby) looks at a picture and says a word, it extracts a word converted from voice by Whisper AI. If it matches the word in the image, the correct answer is indicated. Finally, the user may check the word and wrong words that fits the score.
Click the video then you can see this service Demo