We release various convolutional neural networks (CNNs) trained on Places365 to the public. Places365 is the latest subset of Places2 Database. There are two versions of Places365: Places365-Standard and Places365-Challenge. The train set of Places365-Standard has ~1.8 million images from 365 scene categories, where there are at most 5000 images per category. We have trained various baseline CNNs on the Places365-Standard and released them as below. Meanwhile, the train set of Places365-Challenge has extra 6.2 million images along with all the images of Places365-Standard (so totally ~8 million images), where there are at most 40,000 images per category. Places365-Challenge will be used for the Places2 Challenge 2016 to be held in conjunction with the ILSVRC and COCO joint workshop at ECCV 2016.
The data Places365-Standard and Places365-Challenge are released at Places2 website.
- AlexNet-places365: deploy weights
- GoogLeNet-places365: deploy weights
- VGG16-places365: deploy weights
- VGG16-hybrid1365: deploy weights
- ResNet152-places365 fine-tuned from ResNet152-ImageNet: deploy weights
- ResNet152-hybrid1365: deploy weights
- ResNet152-places365 trained from scratch using Torch: torch model converted caffemodel:deploy weights. It is the original ResNet with 152 layers. On the validation set, the top1 error is 45.26% and the top5 error is 15.02%.
- ResNet50-places365 trained from scratch using Torch: torch model. It is Preact ResNet with 50 layers. The top1 error is 44.82% and the top5 error is 14.71%.
- To use the alexnet and vgg16 caffemodels in Torch, use the torch library loadcaffe, where you could simply load the caffe model use the following commands. But note that the input image scale should be from 0-255, which is different to the 0-1 scale in the previous resnet Torch models trained from scratch in fb.resnet.torch.
require 'loadcaffe'
model = loadcaffe.load('deploy_alexnet_places365.prototxt', 'alexnet_places365.caffemodel', 'cudnn')
- PyTorch Places365 models: AlexNet, ResNet18, ResNet50, DenseNet161. The models are trained in Python2.7+PyTorch 0.2, see this issue if you run into some format errors. You don't need to untar the pytorch model files, refer to the following placesCNN demo code to see how to load the model. Run basic code to get the scene prediction from PlacesCNN:
python run_placesCNN_basic.py
RESULT ON http://places.csail.mit.edu/demo/12.jpg
0.519 -> patio
0.394 -> restaurant_patio
0.018 -> beer_garden
0.017 -> diner/outdoor
0.016 -> courtyard
or run unified code to predict scene categories, indoor/outdoor type, scene attributes, and the class activation map together from PlacesCNN:
python run_placesCNN_unified.py
RESULT ON http://places.csail.mit.edu/demo/6.jpg
--TYPE: indoor
--SCENE CATEGORIES:
0.690 -> food_court
0.163 -> cafeteria
0.033 -> dining_hall
0.022 -> fastfood_restaurant
0.016 -> restaurant
--SCENE ATTRIBUTES:
no horizon, enclosed area, man-made, socializing, indoor lighting, cloth, congregating, eating, working
Class activation map is output as cam.jpg

- Train PlacesCNN using Pytorch. The training script is at here. Download the Places365 standard easyformat split at here. Untar it to some folder. Then run the following:
python train_placesCNN.py -a resnet18 /xxx/yyy/places365standard_easyformat
The category index file is the file. Here we combine the training set of ImageNet 1.2 million data with Places365-Standard to train VGG16-hybrid1365 model, its category index file is the file. The indoor and outdoor labels for the categories is in the file. The scene hierarchy is listed at here, with a simple browswer at here.
The performance of the baseline CNNs is listed below. ResidualNet's performance will be updated soon. We use the class score averaged over 10-crops of each testing image to classify. Here we also fine-tune the resNet152 on Places365-standard, for 10 crop average it has 85.08% on the validation set and 85.07% on the test set for top-5 accuracy.
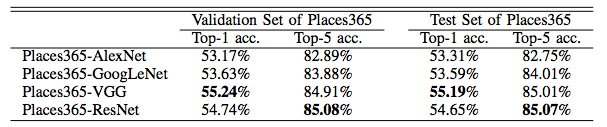
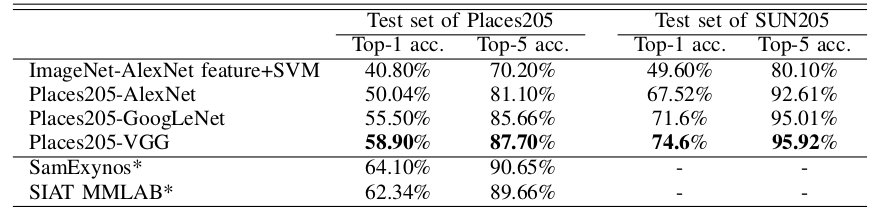
As comparison, we list the performance of the baseline CNNs trained on Places205 as below. There are 160 more scene categories in Places365 than the Places205, the top-5 accuracy doesn't drop much.
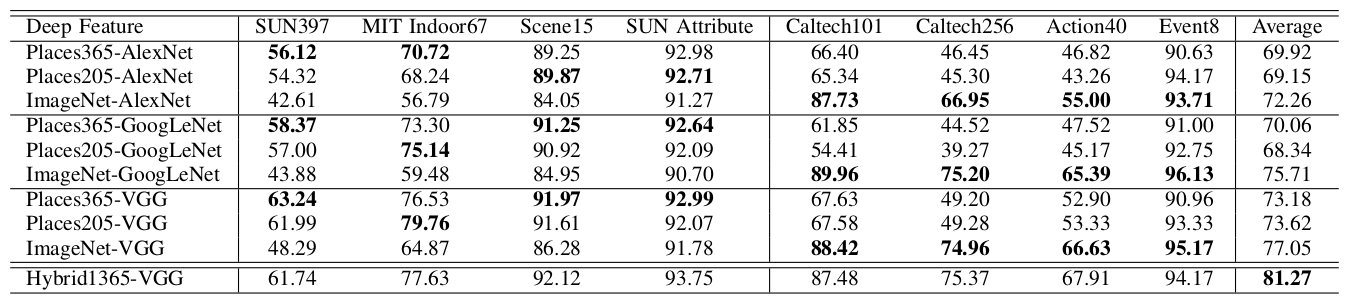
The performance of the deep features of Places365-CNNs as generic visual features is listed below ResidualNets' performances will be included soon. The setup for each experiment is the same as the ones in our NIPS'14 paper
Some qualitative prediction results using the VGG16-Places365:

Link: Places2 Database, Places1 Database
Please cite the following IEEE Transaction on Pattern Analysis and Machine Intelligence paper if you use the data or pre-trained CNN models.
@article{zhou2017places,
title={Places: A 10 million Image Database for Scene Recognition},
author={Zhou, Bolei and Lapedriza, Agata and Khosla, Aditya and Oliva, Aude and Torralba, Antonio},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2017},
publisher={IEEE}
}
Places dataset development has been partly supported by the National Science Foundation CISE directorate (#1016862), the McGovern Institute Neurotechnology Program (MINT), ONR MURI N000141010933, MIT Big Data Initiative at CSAIL, and Google, Xerox, Amazon and NVIDIA. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation and other funding agencies.
The pretrained places-CNN models can be used under the Creative Common License (Attribution CC BY). Please give appropriate credit, such as providing a link to our paper or to the Places Project Page. The copyright of all the images belongs to the image owners.