Tesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于Google对Tesseract进行改进、消除Bug、优化工作。Tesseract目前已作为开源项目发布在Google Project.
运行环境:
windows10 + python 3.6 + tesseract 4.0.0-beta.1
先看效果:
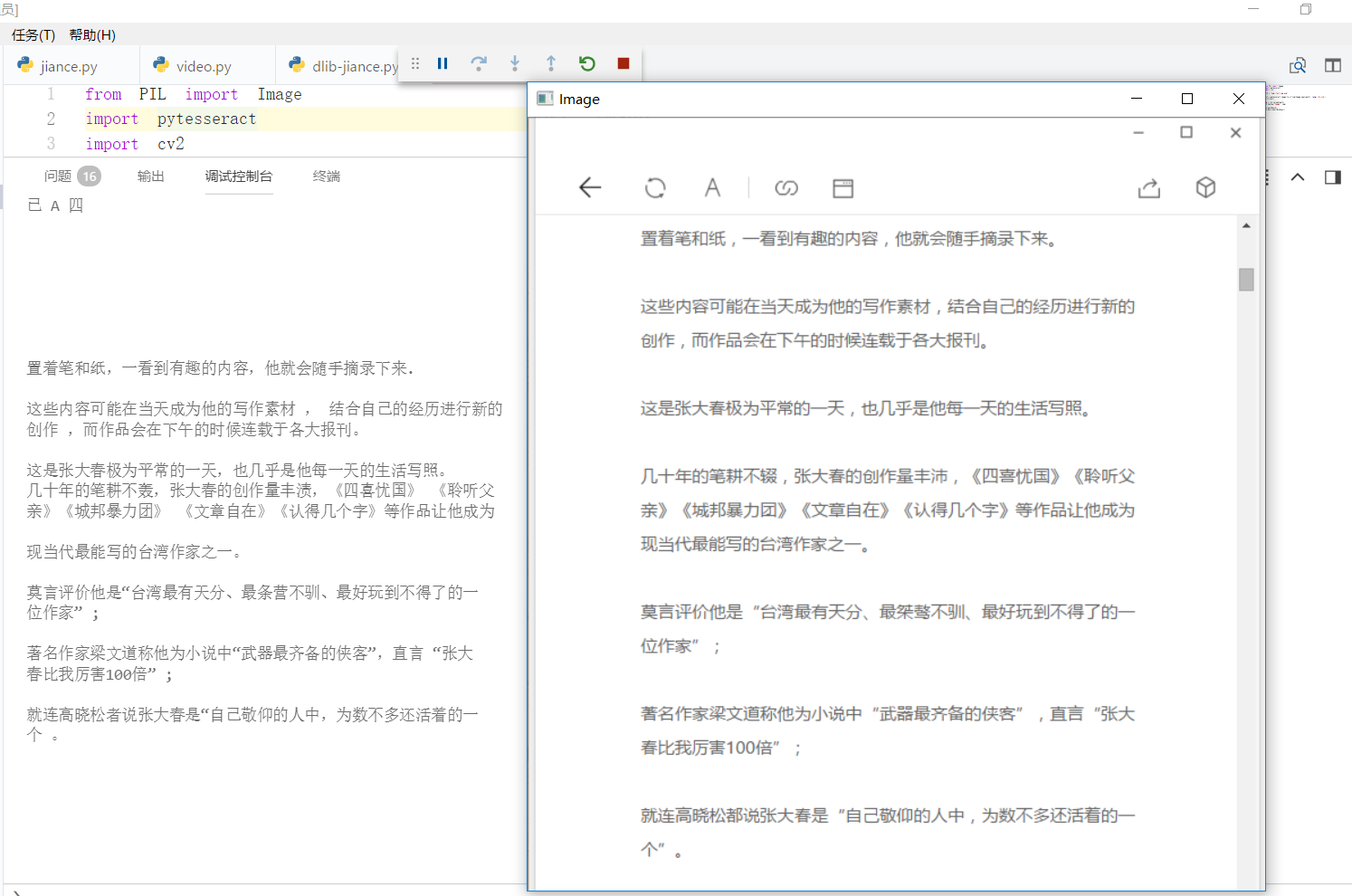
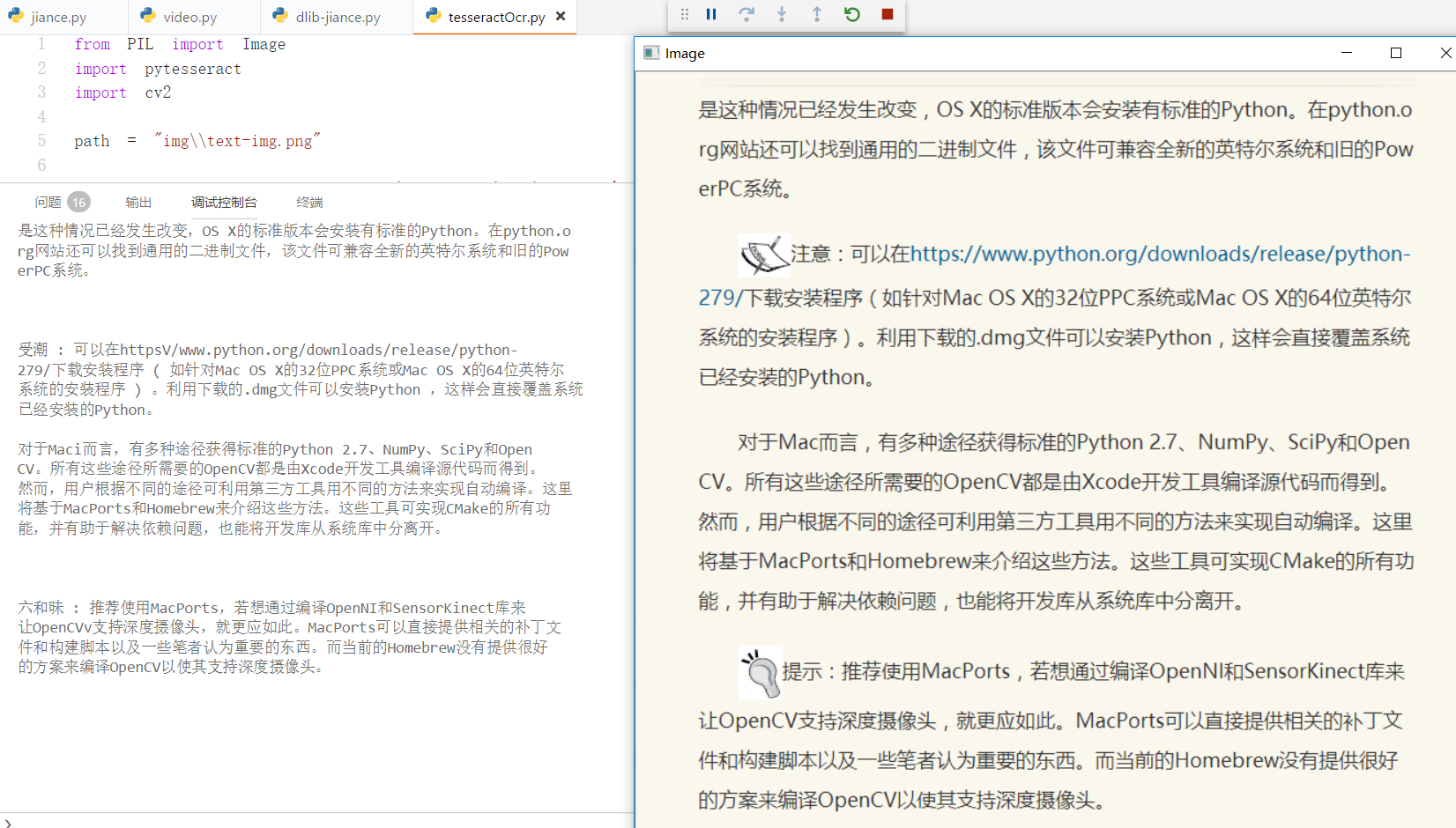
一、安装python模块
pip3 install pytesseract
二、安装tesseract orc 下载地址:https://github.com/UB-Mannheim/tesseract/wiki 点击“tesseract-ocr-w64-setup-v4.0.0-beta.1.20180414.exe”下载安装。
注意:安装的时候选中中文包。
本人安装目录:C:\Users\Administrator\AppData\Local\Tesseract-OCR
使用命令,查看版本号和支持语言:
cd C:\Users\Administrator\AppData\Local\Tesseract-OCR tesseract -v tesseract --list-langs #查看Tesseract-OCR支持语言
三、配置tesseract运行文件
C:\Python36\Lib\site-packages\pytesseract\pytesseract.py 找到文件:
tesseract_cmd = 'tesseract'
修改为:
tesseract_cmd = 'C:/Program Files (x86)/Tesseract-OCR/tesseract.exe'
四、代码识别
from PIL import Image
import pytesseract
path = "img\\text-img.png"
text = pytesseract.image_to_string(Image.open(path), lang='chi_sim')
print(text)
作为非常优秀的Ocr识别库,tesseract当然可以训练自己的数据模型,从而达到为我所用的目的,后续文章会介绍如何训练自己的文字识别库。