这篇文章主要是YouTubeDNN模型召回, 首先,先对YouTubeDNN的召回模型进行简介,然后对代码逻辑进行梳理,最后记录下自己尝试过的实验。
召回模型的目的是在大量YouTube视频中检索出数百个和用户相关的视频来。
这个问题,我们可以看成一个多分类的问题,即用户在某一个时刻点击了某个视频, 可以建模成输入一个用户向量, 从海量视频中预测出被点击的那个视频的概率。
换成比较准确的数学语言描述, 在时刻$t$下, 用户$U$在背景$C$下对每个视频$i$的观看行为建模成下面的公式: $$ P\left(w_{t}=i \mid U, C\right)=\frac{e^{v_{i} u}}{\sum_{j \in V} e^{v_{j} u}} $$ 这里的$u$表示用户向量, 这里的$v$表示视频向量, 两者的维度都是$N$, 召回模型的任务,就是通过用户的历史点击和山下文特征, 去学习最终的用户表示向量$u$以及视频$i$的表示向量$v_i$, 不过这俩还有个区别是$v_i$本身就是模型参数, 而$u$是神经网络的输出(函数输出),是输入与模型参数的计算结果。
YouTube召回模型的结构如下:
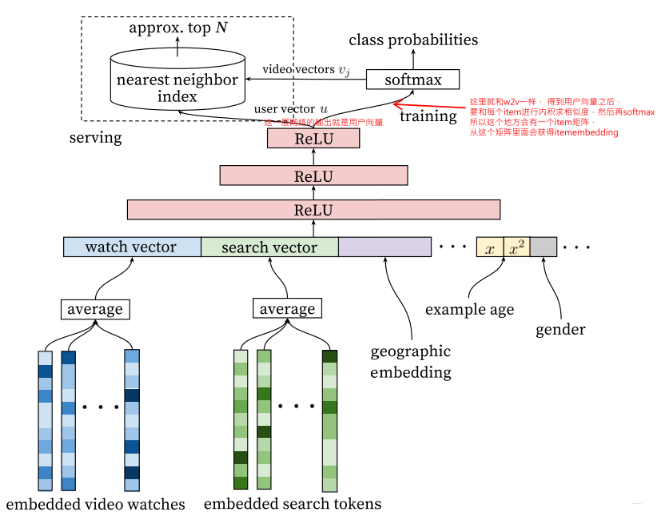
模型结构上比较简单,是一个DNN模型。
它的输入主要是用户侧的特征,包括用户观看的历史video序列, 用户搜索的历史tokens, 然后就是用户的人文特征,比如地理位置, 性别,年龄这些。 这些特征处理上,和之前那些模型的也比较类似,
-
用户历史序列,历史搜索tokens这种序列性的特征: 一般长这样
[item_id5, item_id2, item_id3, ...], 这种id特征是高维稀疏,首先会通过一个embedding层,转成低维稠密的embedding特征,即历史序列里面的每个id都会对应一个embedding向量, 这样历史序列就变成了多个embedding向量的形式, 这些向量一般会进行融合,常见的是average pooling,即每一维求平均得到一个最终向量来表示用户的历史兴趣或搜索兴趣。这里值的一提的是这里的embedding向量得到的方式, 论文中作者这里说是通过word2vec方法计算的, 关于word2vec,这里就不过多解释,也就是每个item事先通过w2v方式算好了的embedding,直接作为了输入,然后进行pooling融合。
除了这种算好embedding方式之外,还可以过embedding层,跟上面的DNN一起训练,这些都是常规操作,之前整理的精排模型里面大都是用这种方式。论文里面使用了用户最近的50次观看历史,用户最近50次搜索历史token, embedding维度是256维, 采用的average pooling。 当然,这里还可以把item的类别信息也隐射到embedding, 与前面的concat起来。
-
用户人文特征, 这种特征处理方式就是离散型的依然是labelEncoder,然后embedding转成低维稠密, 而连续型特征,一般是先归一化操作,然后直接输入,当然有的也通过分桶,转成离散特征,这里不过多整理,特征工程做的事情了。 当然,这里还有一波操作值得注意,就是连续型特征除了用了$x$本身,还用了$x^2$,$logx$这种, 可以加入更多非线性,增加模型表达能力。
这些特征对新用户的推荐会比较有帮助,常见的用户的地理位置, 设备, 性别,年龄等。 -
这里一个比较特色的特征是example age,这个特征后面需要单独整理。
这些特征处理好了之后,拼接起来,就成了一个非常长的向量,然后就是过DNN,这里用了一个三层的DNN, 得到了输出, 这个输出也是向量。这就是该模型前向传播的大体过程。
下面是一些细节的地方:
-
用户向量和item向量在哪里取?
- 用户向量,其实就是全连接的DNN网络的输出向量,在文章中已经标识,因为模型的输入是用户的相关特征, 拼接起来的向量代表了用户的相关特性,DNN在这里的作用是特征交互和降维, 网络的输出就是用户向量。
- item向量: 这个和word2vec的skip-gram模型是一个道理,每个item其实是用两个embedding向量的,比如skip-gram那里就有一个作为中心词时候的embedding矩阵$W$和作为上下文词时候的embedding矩阵$W'$, 一般取的时候会取前面那个$W$作为每个词的词向量。 这里其实一个道理,只不过这里最前面那个item向量矩阵,是通过了w2v的方式训练好了直接作为的输入,如果不事先计算好,对应的是embedding层得到的那个矩阵。 后面的item向量矩阵,就是这里得到用户向量之后,后面进行softmax之前的这个矩阵, YouTubeDNN最终是从这个矩阵里面拿item向量。这个可以在上图中看到。
-
模型是如何训练的?
模型训练的时候, 为了计算更加高效,采用了负采样的方法, 但正负样本的选取,以及训练样本的来源, 还有一些注意事项。
-
首先,训练样本来源于全部的YouTube观看记录,而不仅仅是被推荐的观看记录, 否则对于新视频会难以被曝光,会使最终推荐结果有偏;同时系统也会采集用户从其他渠道观看的视频,从而可以快速应用到协同过滤中;
-
其次, 是训练数据来源于用户的隐式数据, 且用户看完了的视频作为正样本, 注意这里是看完了, 有一定的时长限制, 而不是仅仅曝光点击,有可能有误点的。 而负样本,是从视频库里面随机选取,或者在曝光过的里面随机选取用户没看过的作为负样本。
-
==这里的一个经验==是训练数据中对于每个用户选取相同的样本数, 保证用户在损失函数等权重, 因为这样可以减少高度活跃用户对于loss的影响。可以改进线上A/B测试的效果。
-
这里的==另一个经验==是避免让模型知道不该知道的信息
这里作者举了一个例子是如果模型知道用户最后的行为是搜索了"Taylor Swift", 那么模型可能会倾向于推荐搜索页面搜"Taylor Swift"时搜索的视频, 这个不是推荐模型期望的行为。 解法方法是扔掉时序信息, 历史搜索tokens随机打乱, 使用无序的搜索tokens来表示搜索queryies(average pooling)。
-
-
样本是怎样生成的?
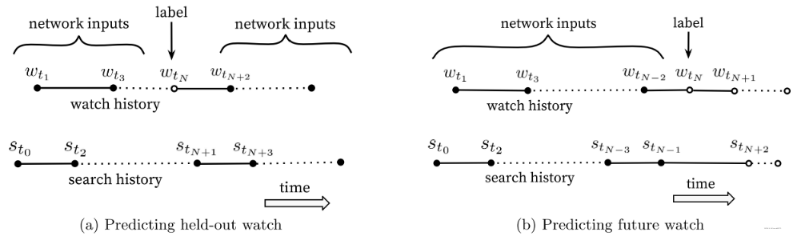
在生成样本的时候, 如果我们的用户比较少,行为比较少, 是不足以训练一个较好的召回模型,此时一个用户的历史观看序列,可以采用滑动窗口的形式生成多个训练样本, 比如一个用户的历史观看记录是"abcdef", 那么采用滑动窗口, 可以是abc预测d, bcd预测e, cde预测f,这样一个用户就能生成3条训练样本。 后面实验里面也是这么做的。 但这时候一定要注意一点,就是信息泄露。
论文中上面这种滑动制作样本的方式依据是用户的"asymmetric co-watch probabilities(非对称观看概率)",即一般情况下,用户开始浏览范围较广, 之后浏览范围逐渐变窄。
下图中的$w_{tN}$表示当前样本, 原来的做法是它前后的用户行为都可以用来产生特征行为输入(word2vec的CBOW做样本的方法)。 而作者担心这一点会导致信息泄露, 模型不该知道的信息是未来的用户行为, 所以作者的做法是只使用更早时间的用户行为来产生特征, 这个也是目前通用的做法。 两种方法的对比如下:
(a)是许多协同过滤会采取的方法,利用全局的观看信息作为输入(包括时间节点N前,N后的观看),这种方法忽略了观看序列的不对称性,而本文中采取(b)所示的方法,只把历史信息当作输入,用历史来预测未来。
模型的测试集, 往往也是用户最近一次观看行为, 后面的实验中,把用户最后一次点击放到了测试集里面去。这样可以防止信息穿越。
-
玄幻特征"example age"
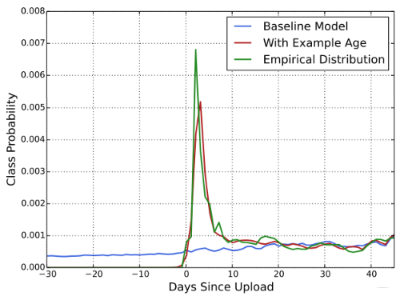
这个特征我想单独拿出来说,是因为这个是和场景比较相关的特征,也是作者的经验传授。 我们知道,视频有明显的生命周期,例如刚上传的视频比之后更受欢迎,也就是用户往往喜欢看最新的东西,而不管它是不是和用户相关,所以视频的流行度随着时间的分布是高度非稳态变化的(下面图中的绿色曲线)
但是我们模型训练的时候,是基于历史数据训练的(历史观看记录的平均),所以模型对播放某个视频预测值的期望会倾向于其在训练数据时间内的平均播放概率(平均热度), 上图中蓝色线。但如上面绿色线,实际上该视频在训练数据时间窗口内热度很可能不均匀, 用户本身就喜欢新上传的内容。 所以,为了让模型学习到用户这种对新颖内容的bias, 作者引入了"example age"这个特征来捕捉视频的生命周期。
"example age"定义为$t_{max}-t$, 其中$t_{max}$是训练数据中所有样本的时间最大值(有的文章说是当前时间,但我总觉得还是选取的训练数据所在时间段的右端点时间比较合适,就比如我用的数据集, 最晚时间是2021年7月的,总不能用现在的时间吧), 而$t$为当前样本的时间。线上预测时, 直接把example age全部设为0或一个小的负值,这样就不依赖于各个视频的上传时间了。
-
线上服务
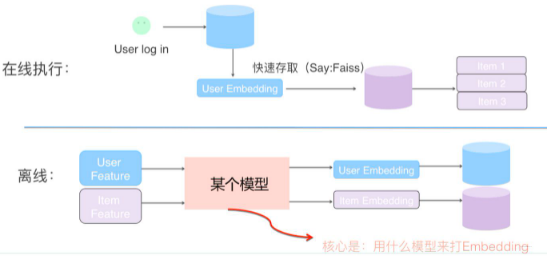
线上服务的时候, YouTube采用了一种最近邻搜索的方法去完成topK推荐,这其实是工程与学术trade-off的结果, model serving过程中对几百万个候选集一一跑模型显然不现实, 所以通过召回模型得到用户和video的embedding之后, 用最近邻搜索的效率会快很多。
我们甚至不用把任何model inference的过程搬上服务器,只需要把user embedding和video embedding存到redis或者内存中就好了。like this:
在线上,可以根据用户兴趣Embedding,采用类似Faiss等高效Embedding检索工具,快速找出和用户兴趣匹配的物品。
这次实验使用的数据集是采样的一个数据集, 拿到数据集之后, 我们需要先划分训练集和测试集
- 测试集: 每个用户的最后一次点击记录
- 训练集: 每个用户除最后一次点击的所有点击记录
这个具体代码就不在这里写了。
user_click_hist_df, user_click_last_df = get_hist_and_last_click(click_df)这么划分的依据,就是保证不能发生数据穿越,拿最后的测试,不能让模型看到。
接下来,就是YouTubeDNN模型的召回,从构造数据集 -> 训练模型 -> 产生召回结果,我写到了一个函数里面去。
def youtubednn_recall(data, topk=200, embedding_dim=8, his_seq_maxlen=50, negsample=0,
batch_size=64, epochs=1, verbose=1, validation_split=0.0):
"""通过YouTubeDNN模型,计算用户向量和文章向量
param: data: 用户日志数据
topk: 对于每个用户,召回多少篇文章
"""
user_id_raw = data[['user_id']].drop_duplicates('user_id')
doc_id_raw = data[['article_id']].drop_duplicates('article_id')
# 类别数据编码
base_features = ['user_id', 'article_id', 'city', 'age', 'gender']
feature_max_idx = {}
for f in base_features:
lbe = LabelEncoder()
data[f] = lbe.fit_transform(data[f])
feature_max_idx[f] = data[f].max() + 1
# 构建用户id词典和doc的id词典,方便从用户idx找到原始的id
user_id_enc = data[['user_id']].drop_duplicates('user_id')
doc_id_enc = data[['article_id']].drop_duplicates('article_id')
user_idx_2_rawid = dict(zip(user_id_enc['user_id'], user_id_raw['user_id']))
doc_idx_2_rawid = dict(zip(doc_id_enc['article_id'], doc_id_raw['article_id']))
# 保存下每篇文章的被点击数量, 方便后面高热文章的打压
doc_clicked_count_df = data.groupby('article_id')['click'].apply(lambda x: x.count()).reset_index()
doc_clicked_count_dict = dict(zip(doc_clicked_count_df['article_id'], doc_clicked_count_df['click']))
train_set, test_set = gen_data_set(data, doc_clicked_count_dict, negsample, control_users=True)
# 构造youtubeDNN模型的输入
train_model_input, train_label = gen_model_input(train_set, his_seq_maxlen)
test_model_input, test_label = gen_model_input(test_set, his_seq_maxlen)
# 构建模型并完成训练
model = train_youtube_model(train_model_input, train_label, embedding_dim, feature_max_idx, his_seq_maxlen, batch_size, epochs, verbose, validation_split)
# 获得用户embedding和doc的embedding, 并进行保存
user_embs, doc_embs = get_embeddings(model, test_model_input, user_idx_2_rawid, doc_idx_2_rawid)
# 对每个用户,拿到召回结果并返回回来
user_recall_doc_dict = get_youtube_recall_res(user_embs, doc_embs, user_idx_2_rawid, doc_idx_2_rawid, topk)
return user_recall_doc_dict这里面说一下主要逻辑,主要是下面几步:
-
用户id和文章id我们要先建立索引-原始id的字典,因为我们模型里面是要把id转成embedding,模型的表示形式会是{索引: embedding}的形式, 如果我们想得到原始id,必须先建立起映射来
-
把类别特征进行label Encoder, 模型输入需要, embedding层需要,这是构建词典常规操作, 这里要记录下每个特征特征值的个数,建词典索引的时候用到,得知道词典大小
-
保存了下每篇文章被点击数量, 方便后面对高热文章实施打压
-
构建数据集
rain_set, test_set = gen_data_set(data, doc_clicked_count_dict, negsample, control_users=True)
这个需要解释下, 虽然我们上面有了一个训练集,但是这个东西是不能直接作为模型输入的, 第一个原因是正样本太少,样本数量不足,我们得需要滑动窗口,每个用户再滑动构造一些,第二个是不满足deepmatch实现的模型输入格式,所以gen_data_set这个函数,是用deepmatch YouTubeDNN的第一个范式,基本上得按照这个来,只不过我加了一些策略上的尝试:
def gen_data_set(click_data, doc_clicked_count_dict, negsample, control_users=False): """构造youtubeDNN的数据集""" # 按照曝光时间排序 click_data.sort_values("expo_time", inplace=True) item_ids = click_data['article_id'].unique() train_set, test_set = [], [] for user_id, hist_click in tqdm(click_data.groupby('user_id')): # 这里按照expo_date分开,每一天用滑动窗口滑,可能相关性更高些,另外,这样序列不会太长,因为eda发现有点击1111个的 #for expo_date, hist_click in hist_date_click.groupby('expo_date'): # 用户当天的点击历史id pos_list = hist_click['article_id'].tolist() user_control_flag = True if control_users: user_samples_cou = 0 # 过长的序列截断 if len(pos_list) > 50: pos_list = pos_list[-50:] if negsample > 0: neg_list = gen_neg_sample_candiate(pos_list, item_ids, doc_clicked_count_dict, negsample, methods='multinomial') # 只有1个的也截断 去掉,当然我之前做了处理,这里没有这种情况了 if len(pos_list) < 2: continue else: # 序列至少是2 for i in range(1, len(pos_list)): hist = pos_list[:i] # 这里采用打压热门item策略,降低高展item成为正样本的概率 freq_i = doc_clicked_count_dict[pos_list[i]] / (np.sum(list(doc_clicked_count_dict.values()))) p_posi = (np.sqrt(freq_i/0.001)+1)*(0.001/freq_i) # p_posi=0.3 表示该item_i成为正样本的概率是0.3, if user_control_flag and i != len(pos_list) - 1: if random.random() > (1-p_posi): row = [user_id, hist[::-1], pos_list[i], hist_click.iloc[0]['city'], hist_click.iloc[0]['age'], hist_click.iloc[0]['gender'], hist_click.iloc[i]['example_age'], 1, len(hist[::-1])] train_set.append(row) for negi in range(negsample): row = [user_id, hist[::-1], neg_list[i*negsample+negi], hist_click.iloc[0]['city'], hist_click.iloc[0]['age'], hist_click.iloc[0]['gender'], hist_click.iloc[i]['example_age'], 0, len(hist[::-1])] train_set.append(row) if control_users: user_samples_cou += 1 # 每个用户序列最长是50, 即每个用户正样本个数最多是50个, 如果每个用户训练样本数量到了30个,训练集不能加这个用户了 if user_samples_cou > 30: user_samples_cou = False # 整个序列加入到test_set, 注意,这里一定每个用户只有一个最长序列,相当于测试集数目等于用户个数 elif i == len(pos_list) - 1: row = [user_id, hist[::-1], pos_list[i], hist_click.iloc[0]['city'], hist_click.iloc[0]['age'], hist_click.iloc[0]['gender'], 0, 0, len(hist[::-1])] test_set.append(row) random.shuffle(train_set) random.shuffle(test_set) return train_set, test_set
关键代码逻辑是首先点击数据按照时间戳排序,然后按照用户分组,对于每个用户的历史点击, 采用滑动窗口的形式,边滑动边构造样本, 第一个注意的地方,是每滑动一次生成一条正样本的时候, 要加入一定比例的负样本进去, 第二个注意最后一整条序列要放到test_set里面。
我这里面加入的一些策略,负样本候选集生成我单独写成一个函数,因为尝试了随机采样和打压热门item采样两种方式, 可以通过methods参数选择。 另外一个就是正样本里面也按照热门实现了打压, 减少高热item成为正样本概率,增加高热item成为负样本概率。 还加了一个控制用户样本数量的参数,去保证每个用户生成一样多的样本数量,打压下高活用户。 -
构造模型输入 这个也是调包的定式操作,必须按照这个写法来:
def gen_model_input(train_set, his_seq_max_len): """构造模型的输入""" # row: [user_id, hist_list, cur_doc_id, city, age, gender, label, hist_len] train_uid = np.array([row[0] for row in train_set]) train_hist_seq = [row[1] for row in train_set] train_iid = np.array([row[2] for row in train_set]) train_u_city = np.array([row[3] for row in train_set]) train_u_age = np.array([row[4] for row in train_set]) train_u_gender = np.array([row[5] for row in train_set]) train_u_example_age = np.array([row[6] for row in train_set]) train_label = np.array([row[7] for row in train_set]) train_hist_len = np.array([row[8] for row in train_set]) train_seq_pad = pad_sequences(train_hist_seq, maxlen=his_seq_max_len, padding='post', truncating='post', value=0) train_model_input = { "user_id": train_uid, "click_doc_id": train_iid, "hist_doc_ids": train_seq_pad, "hist_len": train_hist_len, "u_city": train_u_city, "u_age": train_u_age, "u_gender": train_u_gender, "u_example_age":train_u_example_age } return train_model_input, train_label
上面构造数据集的时候,是把每个特征加入到了二维数组里面去, 这里得告诉模型,每一个维度是啥特征数据。如果相加特征,首先构造数据集的时候,得把数据加入到数组中, 然后在这个函数里面再指定新加入的特征是啥。 下面的那个词典, 是为了把数据输入和模型的Input层给对应起来,通过字典键进行标识。
-
训练YouTubeDNN 这一块也是定式, 在建模型事情,要把特征封装起来,告诉模型哪些是离散特征,哪些是连续特征, 模型要为这些特征建立不同的Input层,处理方式是不一样的
def train_youtube_model(train_model_input, train_label, embedding_dim, feature_max_idx, his_seq_maxlen, batch_size, epochs, verbose, validation_split): """构建youtubednn并完成训练""" # 特征封装 user_feature_columns = [ SparseFeat('user_id', feature_max_idx['user_id'], embedding_dim), VarLenSparseFeat(SparseFeat('hist_doc_ids', feature_max_idx['article_id'], embedding_dim, embedding_name="click_doc_id"), his_seq_maxlen, 'mean', 'hist_len'), SparseFeat('u_city', feature_max_idx['city'], embedding_dim), SparseFeat('u_age', feature_max_idx['age'], embedding_dim), SparseFeat('u_gender', feature_max_idx['gender'], embedding_dim), DenseFeat('u_example_age', 1,) ] doc_feature_columns = [ SparseFeat('click_doc_id', feature_max_idx['article_id'], embedding_dim) # 这里后面也可以把文章的类别画像特征加入 ] # 定义模型 model = YoutubeDNN(user_feature_columns, doc_feature_columns, num_sampled=5, user_dnn_hidden_units=(64, embedding_dim)) # 模型编译 model.compile(optimizer="adam", loss=sampledsoftmaxloss) # 模型训练,这里可以定义验证集的比例,如果设置为0的话就是全量数据直接进行训练 history = model.fit(train_model_input, train_label, batch_size=batch_size, epochs=epochs, verbose=verbose, validation_split=validation_split) return model
然后就是建模型,编译训练即可。这块就非常简单了,当然模型方面有些参数,可以了解下,另外一个注意点,就是这里用户特征和item特征进行了分开, 这其实和双塔模式很像, 用户特征最后编码成用户向量, item特征最后编码成item向量。
-
获得用户向量和item向量 模型训练完之后,就能从模型里面拿用户向量和item向量, 我这里单独写了一个函数:
获取用户embedding和文章embedding def get_embeddings(model, test_model_input, user_idx_2_rawid, doc_idx_2_rawid, save_path='embedding/'): doc_model_input = {'click_doc_id':np.array(list(doc_idx_2_rawid.keys()))} user_embedding_model = Model(inputs=model.user_input, outputs=model.user_embedding) doc_embedding_model = Model(inputs=model.item_input, outputs=model.item_embedding) # 保存当前的item_embedding 和 user_embedding 排序的时候可能能够用到,但是需要注意保存的时候需要和原始的id对应 user_embs = user_embedding_model.predict(test_model_input, batch_size=2 ** 12) doc_embs = doc_embedding_model.predict(doc_model_input, batch_size=2 ** 12) # embedding保存之前归一化一下 user_embs = user_embs / np.linalg.norm(user_embs, axis=1, keepdims=True) doc_embs = doc_embs / np.linalg.norm(doc_embs, axis=1, keepdims=True) # 将Embedding转换成字典的形式方便查询 raw_user_id_emb_dict = {user_idx_2_rawid[k]: \ v for k, v in zip(user_idx_2_rawid.keys(), user_embs)} raw_doc_id_emb_dict = {doc_idx_2_rawid[k]: \ v for k, v in zip(doc_idx_2_rawid.keys(), doc_embs)} # 将Embedding保存到本地 pickle.dump(raw_user_id_emb_dict, open(save_path + 'user_youtube_emb.pkl', 'wb')) pickle.dump(raw_doc_id_emb_dict, open(save_path + 'doc_youtube_emb.pkl', 'wb')) # 读取 #user_embs_dict = pickle.load(open('embedding/user_youtube_emb.pkl', 'rb')) #doc_embs_dict = pickle.load(open('embedding/doc_youtube_emb.pkl', 'rb')) return user_embs, doc_embs
获取embedding的这两行代码是固定操作, 下面做了一些归一化操作,以及把索引转成了原始id的形式。
-
向量最近邻检索,为每个用户召回相似item
def get_youtube_recall_res(user_embs, doc_embs, user_idx_2_rawid, doc_idx_2_rawid, topk): """近邻检索,这里用annoy tree""" # 把doc_embs构建成索引树 f = user_embs.shape[1] t = AnnoyIndex(f, 'angular') for i, v in enumerate(doc_embs): t.add_item(i, v) t.build(10) # 可以保存该索引树 t.save('annoy.ann') # 每个用户向量, 返回最近的TopK个item user_recall_items_dict = collections.defaultdict(dict) for i, u in enumerate(user_embs): recall_doc_scores = t.get_nns_by_vector(u, topk, include_distances=True) # recall_doc_scores是(([doc_idx], [scores])), 这里需要转成原始doc的id raw_doc_scores = list(recall_doc_scores) raw_doc_scores[0] = [doc_idx_2_rawid[i] for i in raw_doc_scores[0]] # 转换成实际用户id try: user_recall_items_dict[user_idx_2_rawid[i]] = dict(zip(*raw_doc_scores)) except: continue # 默认是分数从小到大排的序, 这里要从大到小 user_recall_items_dict = {k: sorted(v.items(), key=lambda x: x[1], reverse=True) for k, v in user_recall_items_dict.items()} # 保存一份 pickle.dump(user_recall_items_dict, open('youtube_u2i_dict.pkl', 'wb')) return user_recall_items_dict
用了用户embedding和item向量,就可以通过这个函数进行检索, 这块主要是annoy包做近邻检索的固定格式, 检索完毕,为用户生成最相似的200个候选item。
以上,就是使用YouTubeDNN做召回的整个流程。 效果如下:


接下来就是评估模型的效果,这里我采用了简单的HR@N计算的, 具体代码看GitHub吧, 结果如下:

这块就比较简单了,简单的整理下我用上面代码做个的实验,尝试了论文里面的几个点,记录下:
- 负采样方式上,尝试了随机负采样和打压高热item两种方式, 从我的实验结果上来看, 带打压的效果略好一点点
- 特征上, 尝试原论文给出的example age的方式,做一个样本的年龄特征出来
这个年龄样本,我是用的训练集的最大时间减去曝光的时间,然后转成小时间隔算的,而测试集里面的统一用0表示, 但效果好差。 看好多文章说这个时间单位是个坑,不知道是小时,分钟,另外这个特征我只做了简单归一化,感觉应该需要做归一化
- 尝试了控制用户数量,即每个用户的样本数量保持一样,效果比上面略差
- 开始模型评估,我尝试用最后一天的,而不是最后一次点击的, 感觉效果不如最后一次点击作为测试集效果好
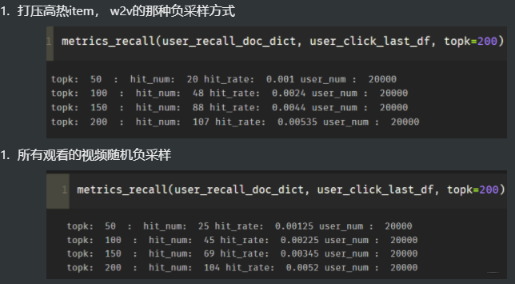

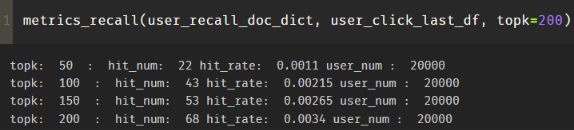
当然,上面实验并没有太大说服力,第一个是我采样的数据量太少,模型本身训练的不怎么样,第二个这些策略相差的并不是很大, 可能有偶然性。
并且我这边做一次实验,要花费好长时间,探索就先到这里吧, example age那个确实是个迷, 其他的感觉起来, 打压高活效果要比不打压要好。
参考: