SDM模型(Sequential Deep Matching Model),是阿里团队在2019年CIKM上的一篇paper。和MIND模型一样,是一种序列召回模型,研究的依然是如何通过用户的历史行为序列去学习到用户的丰富兴趣。 对于MIND,我们已经知道是基于胶囊网络的动态路由机制,设计了一个动态兴趣提取层,把用户的行为序列通过路由机制聚类,然后映射成了多个兴趣胶囊,以此来获取到用户的广泛兴趣。而SDM模型,是先把用户的历史序列根据交互的时间分成了短期和长期两类,然后从短期会话和长期行为中分别采取相应的措施(短期的RNN+多头注意力, 长期的Att Net) 去学习到用户的短期兴趣和长期行为偏好,并巧妙的设计了一个门控网络==有选择==的将长短期兴趣进行融合,以此得到用户的最终兴趣向量。 这篇paper中的一些亮点,比如长期偏好的行为表示,多头注意力机制学习多兴趣,长短期兴趣的融合机制等,又给了一些看待问题的新角度,同时,给出了我们一种利用历史行为序列去捕捉用户动态偏好的新思路。
这篇paper依然是从引言开始, 介绍SDM模型提出的动机以及目前方法存在的不足(why), 接下来就是SDM的网络模型架构(what), 这里面的关键是如何从短期会话和长期行为两个方面学习到用户的短期长期偏好(how),最后,依然是简易代码实现。
大纲如下:
- 背景与动机
- SDM的网络结构与细节
- SDM模型代码复现
这里要介绍该模型提出的动机,即why要有这样的一个模型?
一个好的推荐系统应该是能精确的捕捉用户兴趣偏好以及能对他们当前需求进行快速响应的,往往工业上的推荐系统,为了能快速响应, 一般会把整个推荐流程分成召回和排序两个阶段,先通过召回,从海量商品中得到一个小的候选集,然后再给到排序模型做精确的筛选操作。 这也是目前推荐系统的一个范式了。在这个过程中,召回模块所检索到的候选对象的质量在整个系统中起着至关重要的作用。
淘宝目前的召回模型是一些基于协同过滤的模型, 这些模型是通过用户与商品的历史交互建模,从而得到用户的物品的表示向量,但这个过程是静态的,而用户的行为或者兴趣是时刻变化的, 对于协同过滤的模型来说,并不能很好的捕捉到用户整个行为序列的动态变化。
那我们知道了学习用户历史行为序列很重要, 那么假设序列很长呢?这时候直接用模型学习长序列之间的演进可能不是很好,因为很长的序列里面可能用户的兴趣发生过很大的转变,很多商品压根就没有啥关系,这样硬学,反而会导致越学越乱,就别提这个演进了。所以这里是以会话为单位,对长序列进行切分。作者这里的依据就是用户在同一个Session下,其需求往往是很明确的, 这时候,交互的商品也往往都非常类似。 但是Session与Session之间,可能需求改变,那么商品类型可能骤变。 所以以Session为单位来学习商品之间的序列信息,感觉要比整个长序列学习来的靠谱。
作者首先是先把长序列分成了多个会话, 然后把最近的一次会话,和之前的会话分别视为了用户短期行为和长期行为分别进行了建模,并采用不同的措施学习用户的短期兴趣和长期兴趣,然后通过一个门控机制融合得到用户最终的表示向量。这就是SDM在做的事情,
长短期行为序列联合建模,其实是在给我们提供一种新的学习用户兴趣的新思路, 那么究竟是怎么做的呢?以及为啥这么做呢?
-
对于短期用户行为, 首先作者使用了LSTM来学习序列关系, 而接下来是用一个Multi-head attention机制,学习用户的多兴趣。
先分析分析作者为啥用多头注意力机制,作者这里依然是基于实际的场景出发,作者发现,用户的兴趣点在一个会话里面其实也是多重的。这个可能之前的很多模型也是没考虑到的,但在商品购买的场景中,这确实也是个事实, 顾客在买一个商品的时候,往往会进行多方比较, 考虑品牌,颜色,商店等各种因素。作者认为用普通的注意力机制是无法反映广泛的兴趣了,所以用多头注意力网络。
多头注意力机制从某个角度去看,也有类似聚类的功效,首先它接收了用户的行为序列,然后从多个角度学习到每个商品与其他商品的相关性,然后根据与其他商品的相关性加权融合,这样,相似的item向量大概率就融合到了一块组成一个向量,所谓用户的多兴趣,可能是因为这些行为商品之间,可以从多个空间或者角度去get彼此之间的相关性,这里面有着用户多兴趣的表达信息。
-
用户的长期行为也会影响当前的决策,作者在这里举了一个NBA粉丝的例子,说如果一个是某个NBA球星的粉丝,那么他可能在之前会买很多有关这个球星的商品,如果现在这个时刻想买鞋的时候,大概率会考虑和球星相关的。所以作者说长期偏好和短期行为都非常关键。但是长期偏好或者行为往往是复杂广泛的,就像刚才这个例子里面,可能长期行为里面,买的与这个球星相关商品只占一小部分,而就只有这一小部分对当前决策有用。 这个也是之前的模型利用长期偏好方面存在的问题,那么如何选择出长期偏好里面对于当前决策有用的那部分呢? 作者这里设计了一个门控的方式融合短期和长期,这个想法还是很巧妙的,后面介绍这个东西的时候说下我的想法。
所以下面总结动机以及本篇论文的亮点:
- 动机: 召回模型需要捕获用户的动态兴趣变化,这个过程中利用好用户的长期行为和短期偏好非常关键,而以往的模型有下面几点不足:
- 协同过滤模型: 基于用户的交互进行静态建模,无法感知用户的兴趣变化过程,易召回同质性的商品
- 早期的一些序列推荐模型: 要么是对整个长序列直接建模,但这样太暴力,没法很好的学习商品之间的序列信息,有些是把长序列分成会话,但忽视了一个会话中用户的多重兴趣
- 有些方法在考虑用户的长期行为方面,只是简单的拼接或者加权求和,而实际上用户长期行为中只有很少一小部分对当前的预测有用,这样暴力融合反而会适得其反,起不到效果。另外还有一些多任务或者对抗方法, 在工业场景中不适用等。
- 这些我只是通过我的理解简单总结,详细内容看原论文相关工作部分。
- 亮点:
- SDM模型, 考虑了用户的短期行为和长期兴趣,以会话的形式进行分割,并对这两方面分别建模
- 短期会话由于对当前决策影响比较大,那么我们就学习的全面一点, 首先RNN学习序列关系,其次通过多头注意力机制捕捉多兴趣,然后通过一个Attention Net加权得到短期兴趣表示
- 长期会话通过Attention Net融合,然后过DNN,得到用户的长期表示
- 我们设计了一个门控机制,类似于LSTM的那种门控,能巧妙的融合这两种兴趣,得到用户最终的表示向量
这就是动机与背景总结啦。 那么接下来,SDM究竟是如何学习短期和长期表示,又是如何融合的? 为什么要这么玩?
这里本来直接看模型结构,但感觉还是先过一下问题定义吧,毕竟这次涉及到了会话,还有几个小规则。
- 相同会话ID的商品(后台能获取)算是一个会话
- 相邻的商品,时间间隔小于10分钟(业务自己调整)算一个会话
- 同一个会话中的商品不能超过50个,多出来的放入下一个会话
这样划分开会话之后, 对于用户$u$的短期行为定义是离目前最近的这次会话, 用$\mathcal{S}^{u}=\left[i_{1}^{u}, \ldots, i_{t}^{u}, \ldots, i_{m}^{u}\right]$表示,$m$是序列长度。 而长期的用户行为是过去一周内的会话,但不包括短期的这次会话, 这个用$\mathcal{L}^{u}$表示。网络推荐架构如下:
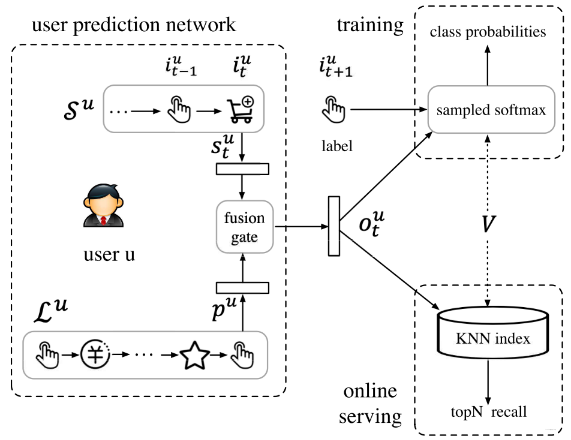
下面要开那三个盲盒操作,即短期行为学习,长期行为学习以及门控融合机制。但在这之前,得先说一个东西,就是输入层这里, 要带物品的side infomation,比如物品的item ID, 物品的品牌ID,商铺ID, 类别ID等等, 那你说,为啥要单独说呢? 之前的模型不也有, 但是这里在利用方式上有些不一样需要注意。
在淘宝的推荐场景中,作者发现, 顾客与物品产生交互行为的时候,不仅考虑特定的商品本身,还考虑产品, 商铺,价格等,这个显然。所以,这里对于一个商品来说,不仅要用到Item ID,还用了更多的side info信息,包括leat category, fist level category, brand,shop。
所以,假设用户的短期行为是$\mathcal{S}^{u}=\left[i_{1}^{u}, \ldots, i_{t}^{u}, \ldots, i_{m}^{u}\right]$, 这里面的每个商品$i_t^u$其实有5个属性表示了,每个属性本质是ID,但转成embedding之后,就得到了5个embedding, 所以这里就涉及到了融合问题。 这里用$\boldsymbol{e}{{i}^u_t} \in \mathbb{R}^{d \times 1}$来表示每个$i_t^u$,但这里不是embedding的pooling操作,而是Concat $$ \boldsymbol{e}{i_{t}^{u}}=\operatorname{concat}\left(\left{\boldsymbol{e}{i}^{f} \mid f \in \mathcal{F}\right}\right) $$ 其中,$\boldsymbol{e}{i}^{f}=\boldsymbol{W}^{f} \boldsymbol{x}{i}^{f} \in \mathbb{R}^{d{f} \times 1}$, 这个公式看着负责,其实就是每个side info的id过embedding layer得到各自的embedding。这里embedding的维度是$d_f$, 等拼接起来之后,就是$d$维了。这个点要注意。
另外就是用户的base表示向量了,这个很简单, 就是用户的基础画像,得到embedding,直接也是Concat,这个常规操作不解释:
$$
\boldsymbol{e}{u}=\operatorname{concat}\left(\left{\boldsymbol{e}{u}^{p} \mid p \in \mathcal{P}\right}\right)
$$
Ok,输入这里说完了之后,就直接开盲盒, 不按照论文里面的顺序来了。想看更多细节的就去看原论文吧,感觉那里面说的有些啰嗦。不如直接上图解释来的明显:
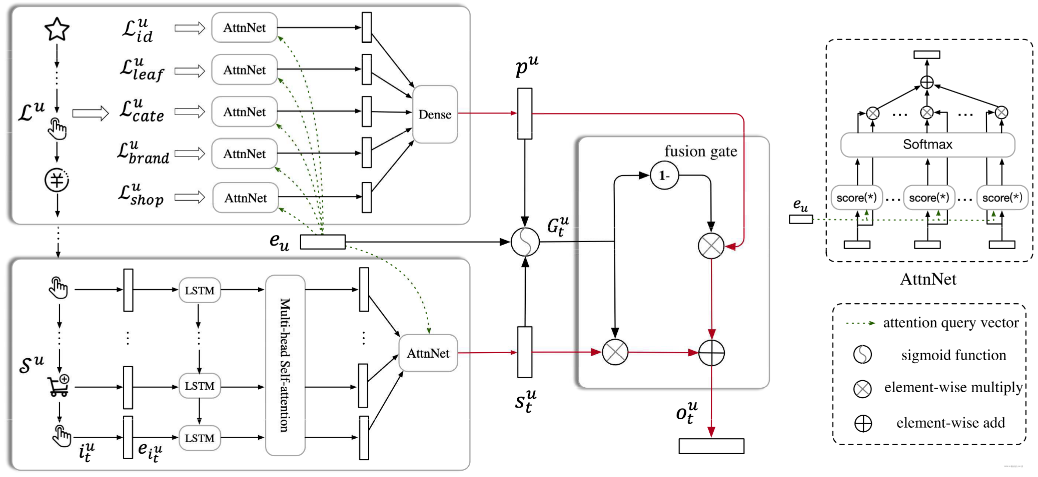
这里短期用户行为是下面的那个框, 接收的输入,首先是用户最近的那次会话,里面各个商品加入了side info信息之后,有了最终的embedding表示$\left[\boldsymbol{e}{i{1}^{u}}, \ldots, \boldsymbol{e}{i{t}^{u}}\right]$。
这个东西,首先要过LSTM,学习序列信息,这个感觉不用多说,直接上公式: $$ \begin{aligned} \boldsymbol{i} \boldsymbol{n}{t}^{u} &=\sigma\left(\boldsymbol{W}{i n}^{1} \boldsymbol{e}{i{t}^{u}}+\boldsymbol{W}{i n}^{2} \boldsymbol{h}{t-1}^{u}+b_{i n}\right) \ f_{t}^{u} &=\sigma\left(\boldsymbol{W}{f}^{1} \boldsymbol{e}{i_{t}^{u}}+\boldsymbol{W}{f}^{2} \boldsymbol{h}{t-1}^{u}+b_{f}\right) \ \boldsymbol{o}{t}^{u} &=\sigma\left(\boldsymbol{W}{o}^{1} \boldsymbol{e}{i}^{u}+\boldsymbol{W}{o}^{2} \boldsymbol{h}{t-1}^{u}+b{o}\right) \ \boldsymbol{c}{t}^{u} &=\boldsymbol{f}{t} \boldsymbol{c}{t-1}^{u}+\boldsymbol{i} \boldsymbol{n}{t}^{u} \tanh \left(\boldsymbol{W}{c}^{1} \boldsymbol{e}{i_{t}^{u}}+\boldsymbol{W}{c}^{2} \boldsymbol{h}{t-1}^{u}+b_{c}\right) \ \boldsymbol{h}{t}^{u} &=\boldsymbol{o}{t}^{u} \tanh \left(\boldsymbol{c}{t}^{u}\right) \end{aligned} $$ 这里采用的是多输入多输出, 即每个时间步都会有一个隐藏状态$h_t^u$输出出来,那么经过LSTM之后,原始的序列就有了序列相关信息,得到了$\left[\boldsymbol{h}{1}^{u}, \ldots, \boldsymbol{h}{t}^{u}\right]$, 把这个记为$\boldsymbol{X}^{u}$。这里的$\boldsymbol{h}{t}^{u} \in \mathbb{R}^{d \times 1}$表示时间$t$的序列偏好表示。
接下来, 这个东西要过Multi-head self-attention层,这个东西的原理我这里就不多讲了,这个东西可以学习到$h_i^u$系列之间的相关性,这个操作从某种角度看,也很像聚类, 因为我们这里是先用多头矩阵把$h_i^u$系列映射到多个空间,然后从各个空间中互求相关性
$$
\text { head }{ }{i}^{u}=\operatorname{Attention}\left(\boldsymbol{W}{i}^{Q} \boldsymbol{X}^{u}, \boldsymbol{W}{i}^{K} \boldsymbol{X}^{u}, \boldsymbol{W}{i}^{V} \boldsymbol{X}^{u}\right)
$$
得到权重后,对原始的向量加权融合。 让$Q_{i}^{u}=W_{i}^{Q} X^{u}$,
这里如果有多头注意力基础的话非常好理解啊,不多解释,可以看我这篇文章补一下。
这是一个头的计算, 接下来每个头都这么算,假设有$h$个头,这里会通过上面的映射矩阵$W$系列,先把原始的$h_i^u$向量映射到$d_{k}=\frac{1}{h} d$维度,然后计算$head_i^u$也是$d_k$维,这样$h$个head进行拼接,正好是$d$维, 接下来过一个全连接或者线性映射得到MultiHead的输出。 $$ \hat{X}^{u}=\text { MultiHead }\left(X^{u}\right)=W^{O} \text { concat }\left(\text { head }{1}^{u}, \ldots, \text { head }{h}^{u}\right) $$
这样就相当于更相似的$h_i^u$融合到了一块,而这个更相似又是从多个角度得到的,于是乎, 作者认为,这样就能学习到用户的多兴趣。
得到这个东西之后,接下来再过一个User Attention, 因为作者发现,对于相似历史行为的不同用户,其兴趣偏好也不太一样。 所以加入这个用户Attention层,想挖掘更细粒度的用户个性化信息。 当然,这个就是普通的embedding层了, 用户的base向量$e_u$作为query,与$\hat{X}^{u}$的每个向量做Attention,然后加权求和得最终向量: $$ \begin{aligned} \alpha_{k} &=\frac{\exp \left(\hat{\boldsymbol{h}}{k}^{u T} \boldsymbol{e}{u}\right)}{\sum_{k=1}^{t} \exp \left(\hat{\boldsymbol{h}}{k}^{u T} \boldsymbol{e}{u}\right)} \ \boldsymbol{s}{t}^{u} &=\sum{k=1}^{t} \alpha_{k} \hat{\boldsymbol{h}}{k}^{u} \end{aligned} $$ 其中$s{t}^{u} \in \mathbb{R}^{d \times 1}$,这样短期行为兴趣就修成了正果。
从长期的视角来看,用户在不同的维度上可能积累了广泛的兴趣,用户可能经常访问一组类似的商店,并反复购买属于同一类别的商品。 所以长期行为$\mathcal{L}^{u}$来自于不同的特征尺度。 $$ \mathcal{L}^{u}=\left{\mathcal{L}{f}^{u} \mid f \in \mathcal{F}\right} $$ 这里面包含了各种side特征。这里就和短期行为那里不太一样了,长期行为这里,是从特征的维度进行聚合,也就是把用户的历史长序列分成了多个特征,比如用户历史点击过的商品,历史逛过的店铺,历史看过的商品的类别,品牌等,分成了多个特征子集,然后这每个特征子集里面有对应的id,比如商品有商品id, 店铺有店铺id等,对于每个子集,过user Attention layer,和用户的base向量求Attention, 相当于看看用户喜欢逛啥样的商店, 喜欢啥样的品牌,啥样的商品类别等等,得到每个子集最终的表示向量。每个子集的计算过程如下: $$ \begin{aligned} \alpha{k} &=\frac{\exp \left(\boldsymbol{g}{k}^{u T} \boldsymbol{e}{u}\right)}{\sum_{k=1}^{\left|\mathcal{L}{f}^{u}\right|} \exp \left(\boldsymbol{g}{k}^{u T} \boldsymbol{e}{u}\right)} \ z{f}^{u} &=\sum_{k=1}^{\left|\mathcal{L}{f}^{u}\right|} \alpha{k} \boldsymbol{g}{k}^{u} \end{aligned} $$ 每个子集都会得到一个加权的向量,把这个东西拼起来,然后过DNN。 $$ \begin{aligned} &z^{u}=\operatorname{concat}\left(\left{z{f}^{u} \mid f \in \mathcal{F}\right}\right) \ &\boldsymbol{p}^{u}=\tanh \left(\boldsymbol{W}^{p} z^{u}+b\right) \end{aligned} $$ 这里的$\boldsymbol{p}^{u} \in \mathbb{R}^{d \times 1}$, 这样就得到了用户的长期兴趣表示。
长短期兴趣融合这里,作者发现之前模型往往喜欢直接拼接起来,或者加和,注意力加权等,但作者认为这样不能很好的将两类兴趣融合起来,因为长期序列里面,其实只有很少的一部分行为和当前有关。那么这样的话,直接无脑融合是有问题的。所以这里作者用了一种较为巧妙的方式,即门控机制: $$ G_{t}^{u}=\operatorname{sigmoid}\left(\boldsymbol{W}^{1} \boldsymbol{e}{u}+\boldsymbol{W}^{2} s{t}^{u}+\boldsymbol{W}^{3} \boldsymbol{p}^{u}+b\right) \ o_{t}^{u}=\left(1-G_{t}^{u}\right) \odot p^{u}+G_{t}^{u} \odot s_{t}^{u} $$ 这个和LSTM的这种门控机制很像,首先门控接收的输入有用户画像$e_u$,用户短期兴趣$s_t^u$, 用户长期兴趣$p^u$,经过sigmoid函数得到了$G_{t}^{u} \in \mathbb{R}^{d \times 1}$,用来决定在$t$时刻短期和长期兴趣的贡献程度。然后根据这个贡献程度对短期和长期偏好加权进行融合。
为啥这东西就有用了呢? 实验中证明了这个东西有用,但这里给出我的理解哈,我们知道最终得到的短期或者长期兴趣都是$d$维的向量, 每一个维度可能代表着不同的兴趣偏好,比如第一维度代表品牌,第二个维度代表类别,第三个维度代表价格,第四个维度代表商店等等,当然假设哈,真实的向量不可解释。
那么如果我们是直接相加或者是加权相加,其实都意味着长短期兴趣这每个维度都有很高的保留, 但其实上,万一长期兴趣和短期兴趣维度冲突了呢? 比如短期兴趣里面可能用户喜欢这个品牌,长期用户里面用户喜欢那个品牌,那么听谁的? 你可能说短期兴趣这个占更大权重呗,那么普通加权可是所有向量都加的相同的权重,品牌这个维度听短期兴趣的,其他维度比如价格,商店也都听短期兴趣的?本身存在不合理性。那么反而直接相加或者加权效果会不好。
而门控机制的巧妙就在于,我会给每个维度都学习到一个权重,而这个权重非0即1(近似哈), 那么接下来融合的时候,我通过这个门控机制,取长期和短期兴趣向量每个维度上的其中一个。比如在品牌方面听谁的,类别方面听谁的,价格方面听谁的,只会听短期和长期兴趣的其中一个的。这样就不会有冲突发生,而至于具体听谁的,交给网络自己学习。这样就使得用户长期兴趣和短期兴趣融合的时候,每个维度上的信息保留变得有选择。使得兴趣的融合方式更加的灵活。
==这其实又给我们提供了一种两个向量融合的一种新思路,并不一定非得加权或者拼接或者相加了,还可以通过门控机制让网络自己学==
下面参考DeepMatch,用简易的代码实现下SDM,并在新闻推荐的数据集上进行召回任务。
首先,下面分析SDM的整体架构,从代码层面看运行流程, 然后就这里面几个关键的细节进行说明。
对于SDM模型,由于它是将用户的行为序列分成了会话的形式,所以在构造SDM模型输入方面和前面的MIND以及YouTubeDNN有很大的不同了,所以这里需要先重点强调下输入。
在为SDM产生数据集的时候, 需要传入短期会话的长度以及长期会话的长度, 这样, 对于一个行为序列,构造数据集的时候要按照两个长度分成短期行为和长期行为两种,并且每一种都需要指明真实的序列长度。另外,由于这里用到了文章的side info信息,所以我这里在之前列的基础上加入了文章的两个类别特征分别是cat_1和cat_2,作为文章的side info。 这个产生数据集的代码如下:
"""构造sdm数据集"""
def get_data_set(click_data, seq_short_len=5, seq_prefer_len=50):
"""
:param: seq_short_len: 短期会话的长度
:param: seq_prefer_len: 会话的最长长度
"""
click_data.sort_values("expo_time", inplace=True)
train_set, test_set = [], []
for user_id, hist_click in tqdm(click_data.groupby('user_id')):
pos_list = hist_click['article_id'].tolist()
cat1_list = hist_click['cat_1'].tolist()
cat2_list = hist_click['cat_2'].tolist()
# 滑动窗口切分数据
for i in range(1, len(pos_list)):
hist = pos_list[:i]
cat1_hist = cat1_list[:i]
cat2_hist = cat2_list[:i]
# 序列长度只够短期的
if i <= seq_short_len and i != len(pos_list) - 1:
train_set.append((
# 用户id, 用户短期历史行为序列, 用户长期历史行为序列, 当前行为文章, label,
user_id, hist[::-1], [0]*seq_prefer_len, pos_list[i], 1,
# 用户短期历史序列长度, 用户长期历史序列长度,
len(hist[::-1]), 0,
# 用户短期历史序列对应类别1, 用户长期历史行为序列对应类别1
cat1_hist[::-1], [0]*seq_prefer_len,
# 历史短期历史序列对应类别2, 用户长期历史行为序列对应类别2
cat2_hist[::-1], [0]*seq_prefer_len
))
# 序列长度够长期的
elif i != len(pos_list) - 1:
train_set.append((
# 用户id, 用户短期历史行为序列,用户长期历史行为序列, 当前行为文章, label
user_id, hist[::-1][:seq_short_len], hist[::-1][seq_short_len:], pos_list[i], 1,
# 用户短期行为序列长度,用户长期行为序列长度,
seq_short_len, len(hist[::-1])-seq_short_len,
# 用户短期历史行为序列对应类别1, 用户长期历史行为序列对应类别1
cat1_hist[::-1][:seq_short_len], cat1_hist[::-1][seq_short_len:],
# 用户短期历史行为序列对应类别2, 用户长期历史行为序列对应类别2
cat2_hist[::-1][:seq_short_len], cat2_hist[::-1][seq_short_len:]
))
# 测试集保留最长的那一条
elif i <= seq_short_len and i == len(pos_list) - 1:
test_set.append((
user_id, hist[::-1], [0]*seq_prefer_len, pos_list[i], 1,
len(hist[::-1]), 0,
cat1_hist[::-1], [0]*seq_perfer_len,
cat2_hist[::-1], [0]*seq_prefer_len
))
else:
test_set.append((
user_id, hist[::-1][:seq_short_len], hist[::-1][seq_short_len:], pos_list[i], 1,
seq_short_len, len(hist[::-1])-seq_short_len,
cat1_hist[::-1][:seq_short_len], cat1_hist[::-1][seq_short_len:],
cat2_list[::-1][:seq_short_len], cat2_hist[::-1][seq_short_len:]
))
random.shuffle(train_set)
random.shuffle(test_set)
return train_set, test_set思路和之前的是一样的,无非就是根据会话的长短,把之前的一个长行为序列划分成了短期和长期两个,然后加入两个新的side info特征。
整个SDM模型算是参考deepmatch修改的一个简易版本:
def SDM(user_feature_columns, item_feature_columns, history_feature_list, num_sampled=5, units=32, rnn_layers=2,
dropout_rate=0.2, rnn_num_res=1, num_head=4, l2_reg_embedding=1e-6, dnn_activation='tanh', seed=1024):
"""
:param rnn_num_res: rnn的残差层个数
:param history_feature_list: short和long sequence field
"""
# item_feature目前只支持doc_id, 再加别的就不行了,其实这里可以改造下
if (len(item_feature_columns)) > 1:
raise ValueError("SDM only support 1 item feature like doc_id")
# 获取item_feature的一些属性
item_feature_column = item_feature_columns[0]
item_feature_name = item_feature_column.name
item_vocabulary_size = item_feature_column.vocabulary_size
# 为用户特征创建Input层
user_input_layer_dict = build_input_layers(user_feature_columns)
item_input_layer_dict = build_input_layers(item_feature_columns)
# 将Input层转化成列表的形式作为model的输入
user_input_layers = list(user_input_layer_dict.values())
item_input_layers = list(item_input_layer_dict.values())
# 筛选出特征中的sparse特征和dense特征,方便单独处理
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), user_feature_columns)) if user_feature_columns else []
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), user_feature_columns)) if user_feature_columns else []
if len(dense_feature_columns) != 0:
raise ValueError("SDM dont support dense feature") # 目前不支持Dense feature
varlen_feature_columns = list(filter(lambda x: isinstance(x, VarLenSparseFeat), user_feature_columns)) if user_feature_columns else []
# 构建embedding字典
embedding_layer_dict = build_embedding_layers(user_feature_columns+item_feature_columns)
# 拿到短期会话和长期会话列 之前的命名规则在这里起作用
sparse_varlen_feature_columns = []
prefer_history_columns = []
short_history_columns = []
prefer_fc_names = list(map(lambda x: "prefer_" + x, history_feature_list))
short_fc_names = list(map(lambda x: "short_" + x, history_feature_list))
for fc in varlen_feature_columns:
if fc.name in prefer_fc_names:
prefer_history_columns.append(fc)
elif fc.name in short_fc_names:
short_history_columns.append(fc)
else:
sparse_varlen_feature_columns.append(fc)
# 获取用户的长期行为序列列表 L^u
# [<tf.Tensor 'emb_prefer_doc_id_2/Identity:0' shape=(None, 50, 32) dtype=float32>, <tf.Tensor 'emb_prefer_cat1_2/Identity:0' shape=(None, 50, 32) dtype=float32>, <tf.Tensor 'emb_prefer_cat2_2/Identity:0' shape=(None, 50, 32) dtype=float32>]
prefer_emb_list = embedding_lookup(prefer_fc_names, user_input_layer_dict, embedding_layer_dict)
# 获取用户的短期序列列表 S^u
# [<tf.Tensor 'emb_short_doc_id_2/Identity:0' shape=(None, 5, 32) dtype=float32>, <tf.Tensor 'emb_short_cat1_2/Identity:0' shape=(None, 5, 32) dtype=float32>, <tf.Tensor 'emb_short_cat2_2/Identity:0' shape=(None, 5, 32) dtype=float32>]
short_emb_list = embedding_lookup(short_fc_names, user_input_layer_dict, embedding_layer_dict)
# 用户离散特征的输入层与embedding层拼接 e^u
user_emb_list = embedding_lookup([col.name for col in sparse_feature_columns], user_input_layer_dict, embedding_layer_dict)
user_emb = concat_func(user_emb_list)
user_emb_output = Dense(units, activation=dnn_activation, name='user_emb_output')(user_emb) # (None, 1, 32)
# 长期序列行为编码
# 过AttentionSequencePoolingLayer --> Concat --> DNN
prefer_sess_length = user_input_layer_dict['prefer_sess_length']
prefer_att_outputs = []
# 遍历长期行为序列
for i, prefer_emb in enumerate(prefer_emb_list):
prefer_attention_output = AttentionSequencePoolingLayer(dropout_rate=0)([user_emb_output, prefer_emb, prefer_sess_length])
prefer_att_outputs.append(prefer_attention_output)
prefer_att_concat = concat_func(prefer_att_outputs) # (None, 1, 64) <== Concat(item_embedding,cat1_embedding,cat2_embedding)
prefer_output = Dense(units, activation=dnn_activation, name='prefer_output')(prefer_att_concat)
# print(prefer_output.shape) # (None, 1, 32)
# 短期行为序列编码
short_sess_length = user_input_layer_dict['short_sess_length']
short_emb_concat = concat_func(short_emb_list) # (None, 5, 64) 这里注意下, 对于短期序列,描述item的side info信息进行了拼接
short_emb_input = Dense(units, activation=dnn_activation, name='short_emb_input')(short_emb_concat) # (None, 5, 32)
# 过rnn 这里的return_sequence=True, 每个时间步都需要输出h
short_rnn_output = DynamicMultiRNN(num_units=units, return_sequence=True, num_layers=rnn_layers,
num_residual_layers=rnn_num_res, # 这里竟然能用到残差
dropout_rate=dropout_rate)([short_emb_input, short_sess_length])
# print(short_rnn_output) # (None, 5, 32)
# 过MultiHeadAttention # (None, 5, 32)
short_att_output = MultiHeadAttention(num_units=units, head_num=num_head, dropout_rate=dropout_rate)([short_rnn_output, short_sess_length]) # (None, 5, 64)
# user_attention # (None, 1, 32)
short_output = UserAttention(num_units=units, activation=dnn_activation, use_res=True, dropout_rate=dropout_rate)([user_emb_output, short_att_output, short_sess_length])
# 门控融合
gated_input = concat_func([prefer_output, short_output, user_emb_output])
gate = Dense(units, activation='sigmoid')(gated_input) # (None, 1, 32)
# temp = tf.multiply(gate, short_output) + tf.multiply(1-gate, prefer_output) 感觉这俩一样?
gated_output = Lambda(lambda x: tf.multiply(x[0], x[1]) + tf.multiply(1-x[0], x[2]))([gate, short_output, prefer_output]) # [None, 1,32]
gated_output_reshape = Lambda(lambda x: tf.squeeze(x, 1))(gated_output) # (None, 32) 这个维度必须要和docembedding层的维度一样,否则后面没法sortmax_loss
# 接下来
item_embedding_matrix = embedding_layer_dict[item_feature_name] # 获取doc_id的embedding层
item_index = EmbeddingIndex(list(range(item_vocabulary_size)))(item_input_layer_dict[item_feature_name]) # 所有doc_id的索引
item_embedding_weight = NoMask()(item_embedding_matrix(item_index)) # 拿到所有item的embedding
pooling_item_embedding_weight = PoolingLayer()([item_embedding_weight]) # 这里依然是当可能不止item_id,或许还有brand_id, cat_id等,需要池化
# 这里传入的是整个doc_id的embedding, user_embedding, 以及用户点击的doc_id,然后去进行负采样计算损失操作
output = SampledSoftmaxLayer(num_sampled)([pooling_item_embedding_weight, gated_output_reshape, item_input_layer_dict[item_feature_name]])
model = Model(inputs=user_input_layers+item_input_layers, outputs=output)
# 下面是等模型训练完了之后,获取用户和item的embedding
model.__setattr__("user_input", user_input_layers)
model.__setattr__("user_embedding", gated_output_reshape) # 用户embedding是取得门控融合的用户向量
model.__setattr__("item_input", item_input_layers)
# item_embedding取得pooling_item_embedding_weight, 这个会发现是负采样操作训练的那个embedding矩阵
model.__setattr__("item_embedding", get_item_embedding(pooling_item_embedding_weight, item_input_layer_dict[item_feature_name]))
return model函数式API搭建模型的方式,首先我们需要传入封装好的用户特征描述以及item特征描述,比如:
# 建立模型
user_feature_columns = [
SparseFeat('user_id', feature_max_idx['user_id'], 16),
SparseFeat('gender', feature_max_idx['gender'], 16),
SparseFeat('age', feature_max_idx['age'], 16),
SparseFeat('city', feature_max_idx['city'], 16),
VarLenSparseFeat(SparseFeat('short_doc_id', feature_max_idx['article_id'], embedding_dim, embedding_name="doc_id"), SEQ_LEN_short, 'mean', 'short_sess_length'),
VarLenSparseFeat(SparseFeat('prefer_doc_id', feature_max_idx['article_id'], embedding_dim, embedding_name='doc_id'), SEQ_LEN_prefer, 'mean', 'prefer_sess_length'),
VarLenSparseFeat(SparseFeat('short_cat1', feature_max_idx['cat_1'], embedding_dim, embedding_name='cat_1'), SEQ_LEN_short, 'mean', 'short_sess_length'),
VarLenSparseFeat(SparseFeat('prefer_cat1', feature_max_idx['cat_1'], embedding_dim, embedding_name='cat_1'), SEQ_LEN_prefer, 'mean', 'prefer_sess_length'),
VarLenSparseFeat(SparseFeat('short_cat2', feature_max_idx['cat_2'], embedding_dim, embedding_name='cat_2'), SEQ_LEN_short, 'mean', 'short_sess_length'),
VarLenSparseFeat(SparseFeat('prefer_cat2', feature_max_idx['cat_2'], embedding_dim, embedding_name='cat_2'), SEQ_LEN_prefer, 'mean', 'prefer_sess_length'),
]
item_feature_columns = [SparseFeat('doc_id', feature_max_idx['article_id'], embedding_dim)]这里需要注意的一个点是短期和长期序列的名字,必须严格的short_, prefer_进行标识,因为在模型搭建的时候就是靠着这个去找到短期和长期序列特征的。
逻辑其实也比较清晰,首先是建立Input层,然后是embedding层, 接下来,根据命名选择出用户的base特征列, 短期行为序列和长期行为序列。长期序列的话是过AttentionPoolingLayer层进行编码,这里本质上注意力然后融合,但这里注意的一个点就是for循环,也就是长期序列行为里面的特征列,比如商品,cat_1, cat_2是for循环的形式求融合向量,再拼接起来过DNN,和论文图保持一致。
短期序列编码部分,是item_embedding,cat_1embedding, cat_2embedding拼接起来,过DynamicMultiRNN层学习序列信息, 过MultiHeadAttention学习多兴趣,最后过UserAttentionLayer进行向量融合。 接下来,长期兴趣向量和短期兴趣向量以及用户base向量,过门控融合机制,得到最终的user_embedding。
而后面的那块是为了模型训练完之后,拿用户embedding和item embedding用的, 这个在MIND那篇文章里作了解释。
今天整理的是SDM,这也是一个标准的序列推荐召回模型,主要还是研究用户的序列,不过这篇paper里面一个有意思的点就是把用户的行为训练以会话的形式进行切分,然后再根据时间,分成了短期会话和长期会话,然后分别采用不同的策略去学习用户的短期兴趣和长期兴趣。
- 对于短期会话,可能和当前预测相关性较大,所以首先用RNN来学习序列信息,然后采用多头注意力机制得到用户的多兴趣, 隐隐约约感觉多头注意力机制还真有种能聚类的功效,接下来就是和用户的base向量进行注意力融合得到短期兴趣
- 长期会话序列中,每个side info信息进行分开,然后分别进行注意力编码融合得到
为了使得长期会话中对当前预测有用的部分得以体现,在融合短期兴趣和长期兴趣的时候,采用了门控的方式,而不是普通的拼接或者加和等操作,使得兴趣保留信息变得有选择。
这其实就是这篇paper的故事了,借鉴的地方首先是多头注意力机制也能学习到用户的多兴趣, 这样对于多兴趣,就有了胶囊网络与多头注意力机制两种思路。 而对于两个向量融合,这里又给我们提供了一种门控融合机制。
参考: