开始时间 | 北京时间:2019 年 3 月 27 日,
截止时间 | 北京时间:2019 年 4 月 3 日,
作业要求:在 GitHub 上实现,截止时间前提交项目链接
题目:
有一个 100GB 的文件,里面内容是文本,要求:
- 找出第一个不重复的词
- 只允许扫一遍原文件
- 尽量少的 IO
- 内存限制 16G
提示:
- 注意代码可读性,添加必要的注释(英文)
- 注意代码风格与规范,添加必要的单元测试和文档
- 注意异常处理,尝试优化性能
- 首先以字节流的方式读取 input 文件,将读到的每个词通过哈希运算和取余操作保存到不同的切片文件中。保存的同时附上单词的序号。
- 依次读取每个切片文件到内存中,利用 hashmap 统计每个词的出现频率。
- 在当前切片文件的出现次数为 1 的词中,找出最早出现的那一个词,即序号最小的词。
- 待所有切片文件读取完成后,比较并找出不同切片文件之间序号最小的词。
算法需要在第一步读取整个 input 文件,然后写入到不同的切片文件中,在第二步依次读取所有切片文件,然后统计频率和找出序号最小的词。 整体需要 2 次完整的文件读取,和 1 次完整的文件写入,一共三次 IO 操作。
为了减少文件 IO,首先想到的方法是压缩切片文件,我使用了 golang 标准库中的 gob 序列化单词数据到切片文件中,可以获得较快的序列化速度和较好的压缩效果。
在读取 input 文件的过程中,可以建立一个 hashmap,进行频率统计和单词去重的工作。当读了很多的内容时(快要超过内存限制时),将 hashmap 中的单词通过哈希函数序列化到磁盘上的不同切片文件中,再释放其占用的内存。重复这个过程直到读完。读取分片文件时,一次性读进内存,重新构建一个 hashmap,合并读到的相同的词。和原来直接写入每个单词的做法相比,多了在写入磁盘前使用 hashmap 进行去重的步骤,会极大地较少对磁盘的写入的数据量。
最后,可以在一些细节上进行优化,比如创建的 Map 设定较大的 len,避免迭代过程中进行动态扩容。对迭代过程中临时变量([]byte 类型)设定较大的 cap ,并且每次拿出字符串后就地清空,而不是重新赋值,这样做同样可以减少新申请内存和动态扩容带来的开销。
PS: 新创建的
Map所设定的len默认是 10000。我对一本文学著作(《1984》乔治·奥威尔)进行分析,发现自然语言组成的英文文本数据中,真正出现的英文单词一般不会超过 10000 个,因此取了 10000 作为 Map 默认长度。
硬件: Intel i7-4700MQ / 8G RAM
系统: Windows 10 / Golang 1.11
测试集采用字母表前 11 个字母生成的全排列,总计约 4x10^8 个不同的单词,每个单词长度为11,文件大小约 400M。 通过函数 createTestInput 产生测试集文件。
文件切片数量设置为 10。测试的方法见下方 debug 部分说明。
下图显示了每次 GC 过程中内存的变化情况:
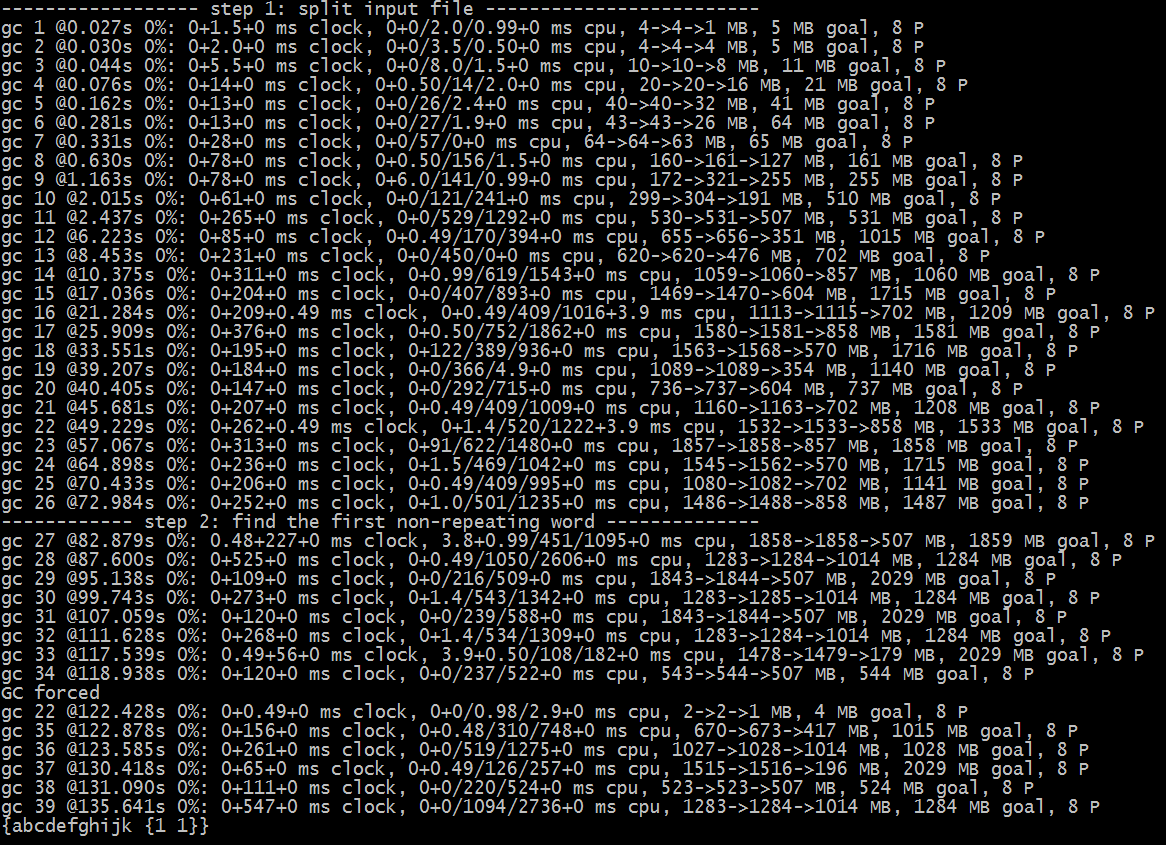
从上图可以看出,整体堆大小一直维持在 2G 以内。每次 GC 都能回收掉一半左右的堆空间。为新建的对象腾出很多空间来。
下图展示了每次即将清理超大对象时的内存分配情况(内存单位为 MB):
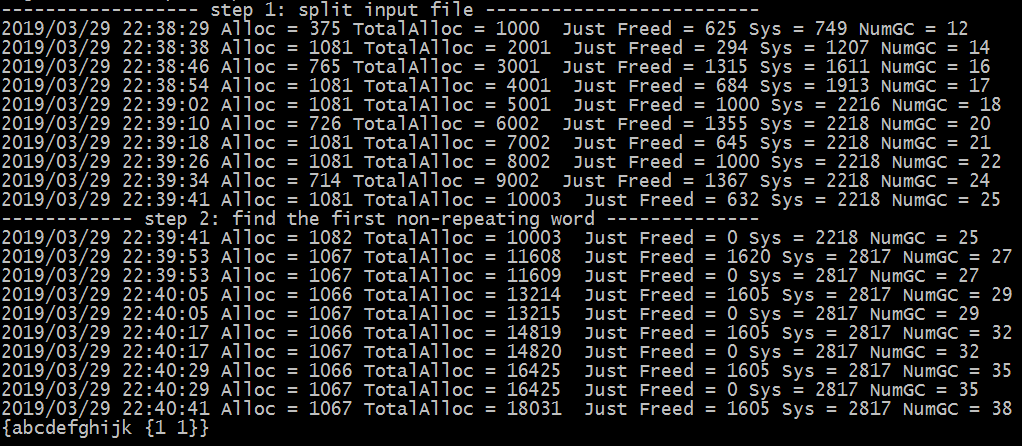
上图显示了程序的内存使用峰值情况,可以看出,程序的内存并不会无限增长,在堆上实际分配的内存最大在 1G 左右。 每次 GC,几乎都能回收 500-1500MB 不等的空闲内存。向系统申请的总内存,不会超过 2.8GB。
综上,通过分而治之的方法解决这个问题,效果拔群。
可以通过 pprof 工具对程序的 cpu 占用和 heap 使用情况进行详细分析,找到性能瓶颈进行进一步的优化。可能的几个优化方向有:
- 使用 goroutine 并发处理,可以充分利用多线程 CPU 资源。
- 采用 MapReduce 的思想,先将 input 文件分成几块,传到不同的机器上,在不同机器上进行 hash 映射分割,将切片文件传到不同的机器中,找各自切片中最早出现的非重复元素,最后合并结果即可。这样可以成倍地提升 CPU 资源和磁盘 IO 能力,但网络带宽可能成为新的瓶颈。
- 采取整存整取的策略(对于HDD磁盘),例如 Block 大小为 64MB,我们写入磁盘时尽量让数据量保持为 64MB 的整数倍,这样避免数据划分太细,被分散在磁盘的各个位置,读写时跨磁盘扇区导致的耗时过长问题。
- 重写一些占用内存较多的或者 CPU 开销较大的标准库函数,以提升性能。比如 strings.ToLower() 函数,参数为字符串变量(string),可以重写一个功能一样的函数,参数改为
[]byte类型的变量,避免了进行类型转换,可以减少 CPU 和内存开销。 - 用 cgo 等手段,手动进行内存管理,可以避免 golang GC带来的开销(GC时会
stop the world)。例如,可以用unsafe.Pointer和reflect.MapHeader自定义一个类似 Map 的数据结构,并且手动为其分配内存和释放内存,达到最高的效率。
go get github.com/Deardrops/pingcapAssignmentcd $GOPATH/src/github.com/Deardrops/pingcapAssignmentgo run . --input=1984.txt --count=10 --mapLen=10000input:input 文件的路径,默认为input.txtcount:切片文件的数目,默认为10mapLen:为每个新建的 Map 对象设定的 len,默认值为10000
go test -v本项目附有完整的单元测试。
主要通过两种方式查看内存分配情况:
一种是设定环境变量 GODEBUG="gctrace=1",然后运行程序,可以看到每次 GC 时堆上的空间变化情况。
另一种是在 main 函数中令全局变量 DEBUG=true,使用 golang 的 runtime 库查看内存分配情况。