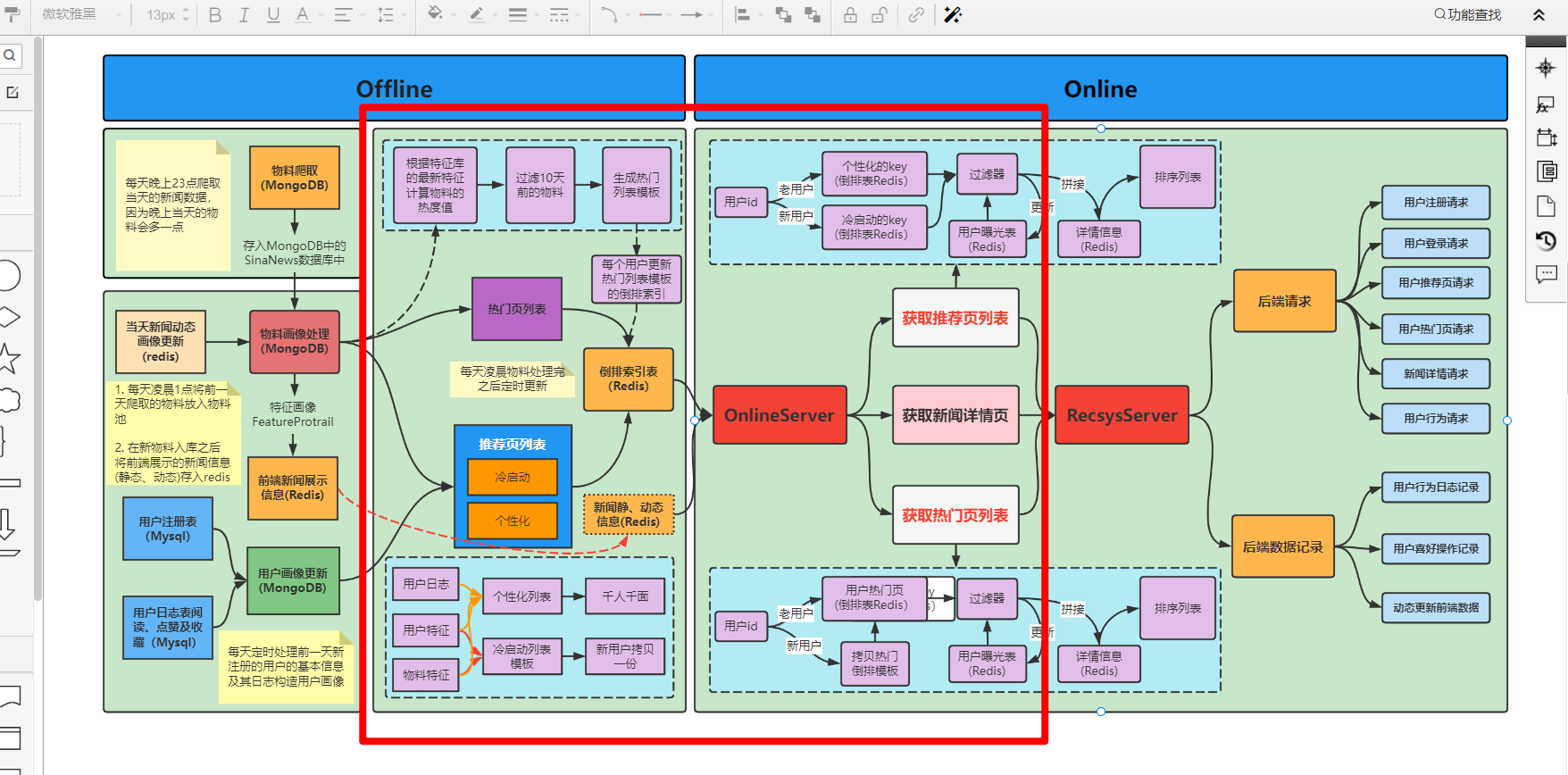
本篇文章主要是讲解推荐系统流程构建,主要包括Offline和Online两个部分。
offline部分主要是基于前面存储好的物料画像和用户画像进行离线计算, 为每个用户提供一个热门页列表和推荐页列表并进行缓存, 方便online服务的列表获取。 所以下面主要帮大家梳理这两个列表的生成以及缓存到redis的流程。
当用户进入系统, 点击热门按钮时, online服务就会为当前用户获取热门页列表, 而这个列表是在用户登录进入的时候, 离线部分事先为用户生成好缓存到了redis中。online服务获取,只需要从redis中拉取即可。
所谓热门页, 就是对于每篇文章,会根据它的发布时间,用户对它的行为记录(获得的点赞数,收藏数和阅读数)去计算该文章的热度信息, 然后根据热度值进行排序得到, 所以计算文章的热门记录, 只需要文章画像的动静态信息即可,天级更新, 逻辑如下:
每天凌晨物料处理完,会得到每篇文章的发布时间(静态特征)以及每篇文章目前为止累计的获赞数,被收藏数和被阅读数(动态特征),这时候,我们就可以遍历物料池中的每篇文章, 拿到文章的发布时间,与当前时间作差得到文章的时效性,然后根据时效性过滤掉发布太久的文章,然后再结合文章的动态特征,基于热度公式,就能计算文章的热度值。每篇文章都有一个热度值,根据热度值排序,就可以得到文章热门列表,把该列表以zset的形式缓存到redis,之所以zset,是因为可以帮助我们根据hot value自动排好序。 这是一份公共的热门列表,这个可以作为每个用户热门列表的初始化状态。
由于每个用户的喜好兴趣不同,对于同一个热门页,点击的文章可能会有所不同,而我们给用户曝光的时候,往往是会先过滤掉对用户曝光过的内容,所以为了每个用户的个性化曝光,当用户登录的时候,我们会给每个用户单独生成一个热门页列表, 初始化状态就是上面的公共列表。之后,用户再去点击热门的时候,就从自己的热门页列表中获取文章了,当然这块是online服务, 我们放后面详细说。
所以,离线热门页列表生成过程总结起来,就是每天遍历物料池, 对于每篇文章,基于动态信息和静态特征计算热度值,并进行热度值排序,生成公共热门模板,作为每个用户单独热门列表的初始。代码如下:
def get_hot_rec_list(self):
"""获取物料的点赞,收藏和创建时间等信息,计算热度并生成热度推荐列表存入redis
"""
# 遍历物料池里面的所有文章
for item in self.feature_protrail_collection.find():
news_id = item['news_id']
news_cate = item['cate']
news_ctime = item['ctime']
news_likes_num = item['likes']
news_collections_num = item['collections']
news_read_num = item['read_num']
news_hot_value = item['hot_value']
#print(news_id, news_cate, news_ctime, news_likes_num, news_collections_num, news_read_num, news_hot_value)
# 时间转换与计算时间差 前提要保证当前时间大于新闻创建时间,目前没有捕捉异常
news_ctime_standard = datetime.strptime(news_ctime, "%Y-%m-%d %H:%M")
cur_time_standard = datetime.now()
time_day_diff = (cur_time_standard - news_ctime_standard).days
time_hour_diff = (cur_time_standard - news_ctime_standard).seconds / 3600
# 只要最近3天的内容
if time_day_diff > 3:
continue
# 计算热度分,这里使用魔方秀热度公式, 可以进行调整, read_num 上一次的 hot_value 上一次的hot_value用加? 因为like_num这些也都是累加上来的, 所以这里计算的并不是增值,而是实时热度吧
# news_hot_value = (news_likes_num * 6 + news_collections_num * 3 + news_read_num * 1) * 10 / (time_hour_diff+1)**1.2
# 72 表示的是3天,
news_hot_value = (news_likes_num * 0.6 + news_collections_num * 0.3 + news_read_num * 0.1) * 10 / (1 + time_hour_diff / 72)
#print(news_likes_num, news_collections_num, time_hour_diff)
# 更新物料池的文章hot_value
item['hot_value'] = news_hot_value
self.feature_protrail_collection.update({'news_id':news_id}, item)
#print("news_hot_value: ", news_hot_value)
# 保存到redis中
self.reclist_redis.zadd('hot_list', {'{}_{}'.format(news_cate, news_id): news_hot_value}, nx=True)当用户进入系统, 映入眼帘的就是推荐页, online服务会给当前用户获取推荐页列表, 这个列表同样是用户进入的时候,离线事先生成缓存到redis中。
推荐页,也正是我们推荐系统发挥效用的部分,对于每个用户,我们会生成不同的推荐页面,这就是我们所知悉的"千人千面",如何做到这一点? 就需要借助已经存好的用户画像和物品画像,制作特征,然后通过模型预测排序,做到所谓的个性化。 当然,对于一个新来的用户,由于我们事先没有存储好用户画像,这就意味着可能没法走个性化推荐流程,这里我们当做冷启动处理。所以这块分成了冷启动和个性化推荐两块进行梳理,逻辑如下:
-
冷启动: 冷启动主要是针对新用户,我们没有太详细的用户画像信息,所以只能通过一些粗略的信息,比如年龄,性别(用户注册时会获取到)等,获取到一些大类别下的文章(适合该年龄,该性别看的文章),然后再根据文章的热度信息,给新用户生成一份冷启动推荐列表。 当然这里只是说了一种简单的方式,冷启动其实也是一种比较复杂的场景,感兴趣同学可以查阅一些其他资料,也欢迎和我们讨论。这里是根据用户的年龄和性别自定义分成了四类人群
def generate_cold_start_news_list_to_redis_for_register_user(self): """给已经注册的用户制作冷启动新闻列表 """ for user_info in self.register_user_sess.query(RegisterUser).all(): if int(user_info.age) < 23 and user_info.gender == "female": redis_key = "cold_start_group:{}".format(str(1)) self.copy_redis_sorted_set(user_info.userid, redis_key) elif int(user_info.age) >= 23 and user_info.gender == "female": redis_key = "cold_start_group:{}".format(str(2)) self.copy_redis_sorted_set(user_info.userid, redis_key) elif int(user_info.age) < 23 and user_info.gender == "male": redis_key = "cold_start_group:{}".format(str(3)) self.copy_redis_sorted_set(user_info.userid, redis_key) elif int(user_info.age) >= 23 and user_info.gender == "male": redis_key = "cold_start_group:{}".format(str(4)) self.copy_redis_sorted_set(user_info.userid, redis_key) else: pass print("generate_cold_start_news_list_to_redis_for_register_user.")
-
个性化: 个性化推荐主要是针对老用户,我们通过正常推荐流程, 捕捉其兴趣爱好,做到个性推荐,优化用户体验。 所以这块走正常推荐流程,比如我们所熟知的召回→排序→重排→个性化列表生成, 召回的目的是根据用户部分特征,从海量物品库,快速找到小部分用户潜在感兴趣的物品交给精排,重点强调快,精排主要是融入更多特征,使用复杂模型,来做个性化推荐,强调准。 而重排侧,主要是结合精排的结果,再加上各种业务策略,比如去重,插入,打散,多样性保证等,主要是技术产品策略主导或改善用户体验的。 所以这几个环节组合起来,以"迅雷不及掩耳漏斗之势",组成了个性化推荐系统的整个架构。由于这是推荐的重点环节, 每个模块都有非常丰富的知识细节,这里就不过多介绍了,后面有机会的话单独整理。
所以, 推荐页列表生成过程总结起来, 首先先根据用户的类型分成两波, 如果是新用户, 就走冷启动推荐流程,通过用户粗略信息,给用户生成一份冷启动推荐列表。 如果是老用户, 就走个性化推荐流程, 通过召回→排序→重排等,给老用户生成一份个性化列表。最终都存储到Redis中。
至此, offline流程结束, 通过offline, 对于每个用户, 我们离线生成好热门页列表, 推荐页列表。
接下来,我们看online。
Online是为用户在使用APP或者系统的过程中触发的行为提供一系列服务,当用户刚进入系统的时候, 会进入新闻的推荐页面,此时系统会为该用户获取推荐页文章并进行展示,当用户进入热门页, 系统就会为该用户获取热门页列表并进行展示, 下面主要介绍这两块线上获取过程中的一些细节。
-
获取推荐页列表: 这个服务在用户刚进入系统,以及在推荐页中浏览文章刷新下拉过程中进行触发,当系统触发该服务的时候, 首先会判断该用户是新用户还是老用户
- 如果是新用户, 就从离线存储好的冷启动列表中读取推荐列表, 选择指定的数目(比如一次触发给用户推荐10篇)的文章推荐,但推荐之前,需要去除已曝光的文章(避免重复曝光,影响用户体验),所以对于每个用户,我们还会记录一份已曝光列表,方便我们去重, 同时,当批文章曝光出去,还要即使更新我们的曝光列表。
- 如果是老用户, 就从离线存储好的个性化推荐列表中读取, 和上面一样, 选择指定数目的文章,去掉曝光,生成最终推荐列表,同时更新用户曝光记录。
- 这样就完成了推荐页的推荐服务。
-
获取热门页列表: 这个服务是用户点击热门页,以及在热门页中浏览文章刷新下来过程中进行触发,当该服务触发的时候,依然会判断新用户和老用户
- 如果是新用户, 需要从离线存储好的公共冷启动模板中为该用户生成一份热门页列表,然后获取,选择指定数目文章推荐,和上面一样,去曝光,生成最终推荐列表,更新曝光记录。
- 如果是老用户, 从离线存储好的该用户热门列表中读取,选择指定数目文章推荐,去曝光,生成最终推荐列表,更新曝光记录。
- 这样就完成了热门页的推荐服务。
代码如下:
def get_hot_list(self, user_id): """热门页列表结果""" hot_list_key_prefix = "user_id_hot_list:" hot_list_user_key = hot_list_key_prefix + str(user_id) user_exposure_prefix = "user_exposure:" user_exposure_key = user_exposure_prefix + str(user_id) # 当数据库中没有这个用户的数据,就从热门列表中拷贝一份 if self.reclist_redis_db.exists(hot_list_user_key) == 0: # 存在返回1,不存在返回0 print("copy a hot_list for {}".format(hot_list_user_key)) # 给当前用户重新生成一个hot页推荐列表, 也就是把hot_list里面的列表复制一份给当前user, key换成user_id self.reclist_redis_db.zunionstore(hot_list_user_key, ["hot_list"]) # 一页默认10个item, 但这里候选20条,因为有可能有的在推荐页曝光过 article_num = 200 # 返回的是一个news_id列表 zrevrange排序分值从大到小 candiate_id_list = self.reclist_redis_db.zrevrange(hot_list_user_key, 0, article_num-1) if len(candiate_id_list) > 0: # 根据news_id获取新闻的具体内容,并返回一个列表,列表中的元素是按照顺序展示的新闻信息字典 news_info_list = [] selected_news = [] # 记录真正被选了的 cou = 0 # 曝光列表 print("self.reclist_redis_db.exists(key)",self.exposure_redis_db.exists(user_exposure_key)) if self.exposure_redis_db.exists(user_exposure_key) > 0: exposure_list = self.exposure_redis_db.smembers(user_exposure_key) news_expose_list = set(map(lambda x: x.split(':')[0], exposure_list)) else: news_expose_list = set() for i in range(len(candiate_id_list)): candiate = candiate_id_list[i] news_id = candiate.split('_')[1] # 去重曝光过的,包括在推荐页以及hot页 if news_id in news_expose_list: continue # TODO 有些新闻可能获取不到静态的信息,这里应该有什么bug # bug 原因是,json.loads() redis中的数据会报错,需要对redis中的数据进行处理 # 可以在物料处理的时候过滤一遍,json无法load的新闻 try: news_info_dict = self.get_news_detail(news_id) except Exception as e: with open("/home/recsys/news_rec_server/logs/news_bad_cases.log", "a+") as f: f.write(news_id + "\n") print("there are not news detail info for {}".format(news_id)) continue # 需要确认一下前端接收的json,key需要是单引号还是双引号 news_info_list.append(news_info_dict) news_expose_list.add(news_id) # 注意,原数的key中是包含了类别信息的 selected_news.append(candiate) cou += 1 if cou == 10: break if len(selected_news) > 0: # 手动删除读取出来的缓存结果, 这个很关键, 返回被删除的元素数量,用来检测是否被真的被删除了 removed_num = self.reclist_redis_db.zrem(hot_list_user_key, *selected_news) print("the numbers of be removed:", removed_num) # 曝光重新落表 self._save_user_exposure(user_id,news_expose_list) return news_info_list else: #TODO 临时这么做,这么做不太好 self.reclist_redis_db.zunionstore(hot_list_user_key, ["hot_list"]) print("copy a hot_list for {}".format(hot_list_user_key)) # 如果是把所有内容都刷完了再重新拷贝的数据,还得记得把今天的曝光数据给清除了 self.exposure_redis_db.delete(user_exposure_key) return self.get_hot_list(user_id)
至此, Online部分的推荐相关流程结束, Online的推荐流程,主要为用户的推荐页以及热门页产生推荐列表进行服务。