Description of the approach : https://medium.com/@CVxTz/audio-classification-a-convolutional-neural-network-approach-b0a4fce8f6c
Requirement : Keras, tensorflow, numpy, librosa
Audio Classification can be used for audio scene understanding which in turn is
important so that an artificial agent is able to understand and better interact
with its environment.
This is the motivation for this blog post, I will
present two different ways that you can go about doing audio classification
based on convolutions.
We will base our experiments on the dataset available at (https://www.kaggle.com/c/freesound-audio-tagging) which is a data-set of annotated audio segments of different lengths and out of 41 classes like “Acoustic_guitar”, “Applause”, “Bark” …
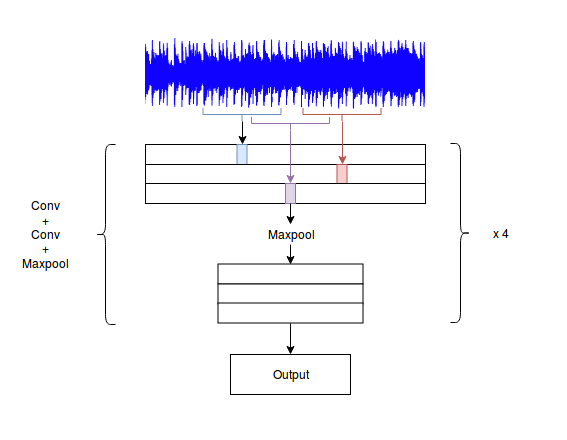
First Approach : Raw audio wave and 1D convolutions
The most straightforward way to do it is to feed the raw wave to a cascade of 1D convolutions and finally produce the class probabilities.
Second Approach : Log-Mel spectrogram
One more advanced approach to audio classification is using Mel-spectrogram instead of raw audio wave.
Mel spectrogram “is a representation of the short-term power spectrum of a sound, based on a linear cosine transform of a log power spectrum on a nonlinear mel scale of frequency.” — https://en.wikipedia.org/wiki/Mel-frequency_cepstrum
Mel spectrogram transform the input raw sequence to a 2D feature map where one dimension represents time and the other one represents frequency and the values represents amplitude.
Results (Mean Average Precision @ 3 ) :
1D : 0.754
2D : 0.849
Average predictions of the two :0.883
2D mel Model outperforms the 1D raw wave model but the average of the two outperforms each individual model significantly. This is probably because each model learns different representations and make different kind of mistakes and by averaging them each model corrects the errors of the other in some way.
Code to reproduce the results is available at : https://github.com/cvxtz/audio_classification